0304
파일불러오기
from glob import glob
glob ("data/apt*.csv"))glob함수를 이용하면 인자로 받은 패턴과 이름이 일치하는 모든 파일과 디렉터리를 반환한다
이를 통해 apt*는 apt로 시작하는 파일을 가져와라~
데이터 타입 변경하기
pd.to_numeric - 함수를 이용한 문자열 칼럼의 숫자형으로 변경
이떄 쓸수있는 옵션 3개
ㄱ. errors = 'ignore' = 숫자로 변경할수 없을시 원본 그대로 반환
ㄴ.errors = 'coerce' = 숫자로 변경할수 없을시 NaN으로 반환
ㄷ. errors = 'raise' = 숫자로 변경할수 없는데이터라면 에러후 중단
astype() 메소드를 이용한 문자열 칼럼의 숫자형 변환 ex astype(int)
컬럼문구를 변경하기

규모구분을 전용면적으로 변경하기
df_last["전용면적"] = df_last["규모구분"].str.replace("전용면적|제곱미터이하", "" ,regex =True)
# .str을 통해 문자열로 변경후 replace로 문자열을 변경
# 이떄 regex =True을 사용하여 정규 표현식으로 문자열 치환을 한다는 의미
df_last["전용면적"] = df_last["전용면적"].str.replace("제곱미터초과","~")
df_last["전용면적"] = df_last["전용면적"].str.replace(" ","")
df_last["전용면적"].unique()array(['모든면적', '60', '60~85', '85~102', '102~'], dtype=object)필요없는컬럼 제거하기drop를 통해 컬럼을 제거한다
df_last = df_last.drop(columns=["규모구분","분양가격"])
이떄 주의할것 axis 0:행, 1:열이다!

pandas.melt(df,
id_vars=['col1', 'col2', ...],
value_vars=['col3', 'col4', ...],
var_name='var_name',
value_name='value_name',
ignore_index=True)
# df = melt를 적용할 DataFrame
# id_vars=['col1', 'col2', ...] = 기준 column이 될 column들
# value_vars=['col3', 'col4', ...] = unpivot(melt)의 대상이 될 column들
# var_name='var_name' = unpivot(melt) 후 id_vars에 명시된 데이터들이 담긴 column 이름
# value_name='value_name' = unpivot(melt) 후 value_vars에 명시된 데이터들이 담긴 column 이름
# ignore_index=True/False (defalut = True)
# True = unpivot(melt) 후 결과 dataframe의 index를 reset한다.
# False = unpivot(melt) 후 결과 dataframe의 index를 reset하지 않고 원본 DataFrame의 index를 사용한다.가로데이터를 세로데이터로 바꿔줍니다
즉 열에있던 데이터를 행으로 바꿔줍니다
df_first_melt = pd.melt(df_first, id_vars="지역")

컬럼 string-handling하기
https://pandas.pydata.org/pandas-docs/stable/reference/series.html#string-handling
목적 기간을 년,월로 분리하기
방법 1.str로 변경해서 spilt으로 자룬후 슬라이싱
df_first_melt["연도"] = df_first_melt["기간"].str.split("년", expand=True)[0].astype(int)
df_first_melt["월"] = df_first_melt["기간"].str.split("년", expand=True)[1].str[:-1].astype(int)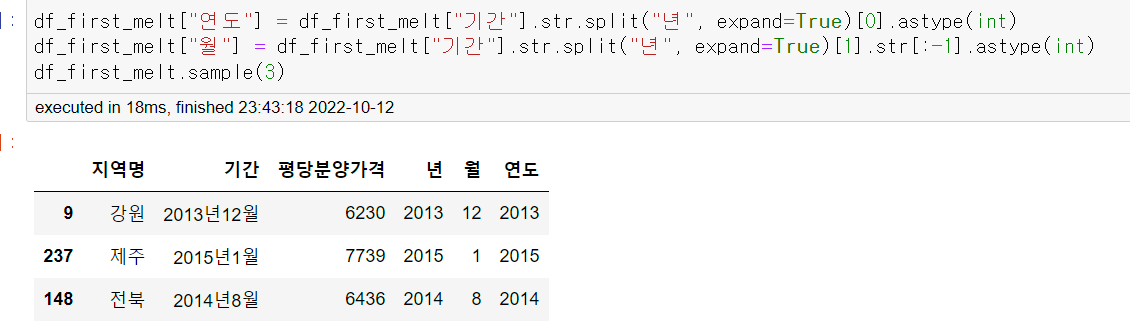
방법 2 str로 변경후 replcae사용
df_first_melt["월"] = df_first_melt["기간"].str.split("년", expand=True)[1].str.replace("월", "").astype(int)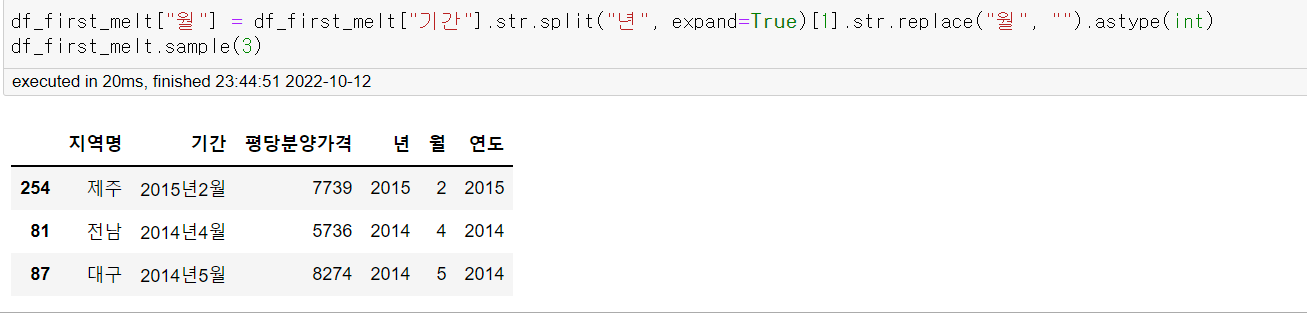
방법 3 lambda함수 사용하기
df_first_melt["연도"] = df_first_melt["기간"].map(lambda x : int(x.split("년")[0]))
df_first_melt["월"] = df_first_melt["기간"].map(lambda x : x.split("년")[1][:-1])
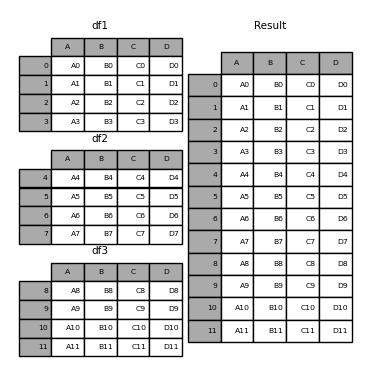
concat으로 데이터프레임을 합칠수있다
그룹바이
df.groupby(["인덱스로 사용할 컬럼명"])["계산할 컬럼 값"].연산()groupby를 통해 데이터를 그룹화해지고 연산해줄수있다

크기는 size(),평균은 mean(), 합계는 sum()

피벗테이블
pd.pivot_table(df,index = "행 위치에 들어갈 열",columns = '열 위치에 들어갈 열' values = '데이터로 사용할 열)
인용자료 :
멋쟁이사자처럼 AI School 7기 박조은 강사의 자료
'TIL > 파이썬' 카테고리의 다른 글
| 22.11.01 시각화 방식비교 lambda,map()함수 (0) | 2022.11.02 |
|---|---|
| 22.10.30 (0) | 2022.10.30 |
| 오늘 공부한거 요약해보기 (0) | 2022.10.10 |
| 시리즈와 데이터프레임 (0) | 2022.10.06 |
| 프로그래머스 문제풀기 - 핸드폰 번호 가리기 (0) | 2022.10.02 |

댓글