희소값
범주가 적은 값을 피처로 만들어 줄떄 문제점
1. 오버피팅이 발생할수 있다
2. one-hot-encoding을 사용할 경우 피쳐가 너무 많이 생겨 불필요하게 자원을 많이 소모할 수 있다.
너무 희소한 값이라면 one-hot-encoding 하기전 전처리 방법
1. 기타로 묶어준다
2.아예 결측치로 처리하고 pd.get_dummies 혹은 OneHotEncoder를 사용했을 때 인코딩 하지 않습니다
표준정규분포화
만드는 순서
로그변환 -> 스케일링
왜 데이터를 정규분포 형태로 만들어주면 머신러닝이나 딥러닝에서 더 나은 성능을 낼까요?
피처의 범위가 다르면 피처간 비교가 어려우며 경사하강법(Gradient Descent)이나 KNN, Clustering 등의 거리 기반 알고리즘에서는 머신러닝이 제대로 작동하지 않습니다.
한쪽에 몰려있는 경우보다 고르게 분포되어 있을 경우 데이터의 특성을 보다 고르게 학습할 수 있기 때문에
음수 값은 어떻게 로그를 취해줄까요?
모든 값에 '최소값 +1'을 해준 다음 log를 취한다.
(모든값이 양수일떈 그냥 1을 더해주면 되지만 -1000이 최소값인경우 라면 최소값+1인 1001을 더해준다 )
log 적용
np.log(x + '최소값+1')
되돌리는법
np.exp(x) - ('최소값+1')
변수 transformation
분포를 정규분포 형태로 만드는 것
표준정규분포 형태로 만들기 : transformation 후 scaling
정규분포 형태가 머신러닝과 딥러닝에 더 나은 성능을 내는 이유
- 데이터의 특성을 더 고르게 학습할 수 있음
- 전처리 할 속성의 영향을 같은 선상에서 비교할 수음
- 대체로 데이터는 가운데에 분포하는 형태가 일 것이기 때문
log transformation
- 값이 모두 0보다 크고, 0보다 작은 값이 존재할 때 : 1을 더하고 로그를 취함
- 음수에 로그를 취하는 방법 : (최솟값의 절대값 + 1)을 더하고 로그를 취함
- 본래 값으로 복원 : np.exp(x) - (log전에 더했던 값)
이산화
정의
연속된 수치 데이터를 범주화 해주는 기능이다.
cut, qcut
| cut | qcut |
| 절대 평가 | 상대 평가 |
| 동일한 너비 n개의 bins로 나눈다 | 가능한 값 범위에 따라 n개의 bins로 나눈다 (알고리즘 성능 향상에 도움이 된다) |
이 방법은 RFM 기법에서도 종종 사용되는 방법으로 비즈니스 분석에서 다룰 예정!
RFM?
Recency, Frequency, Monetary => 고객이 얼마나 최근에, 자주, 많이 구매했는지를 분석할 때 사용합니다
이상화의 장점
연속된 수치 데이터를 구간화합니다. => 머신러닝 알고리즘에 힌트를 줄 수도 있습니다
구간의 기준은 어떻게 정해야 하는가?
DA를 통해 어떻게 나누는 것이 예측에 도움이 될지 확인합니다.
연속된 수치데이터를 나누는 기준에 따라 모델의 성능에 영향을 주게 됩니다
하지만 오히려 잘못나누면 모델의 성능이 떨어질 수도 있습니다
트리모델이라면 너무 잘게 데이터를 나누지 않아 일반화 하는데 도움이 될 수도 있습니다.
인코딩
저번 TIL글 참조
| Ordinal-Encoding | One-Hot-Encoding | |
| 정의 | Categorical Feature의 고유값들을 임의의 숫자로 바꿈 | Categorical Feature를 다른 bool 변수로 대체하여 해당 관찰에 대해 특정 레이블이 참인지 여부를 나타냄 |
| 특징 | 임의의 숫자를 지정 가능 (지정하지 않으면 0부터 1씩 증가하는 정수로 지정) 순서가 있는 명목형 데이터에 사용 (ex 분기) 1차원 형태로 반환 |
순서가 없는 명목형 데이터에 사용 (ex 좋아하는 음료) matrix, 2차원 형태로 반환 |
| 장점 | 간단하고, 직관적이다 | 해당 Feature의 모든 정보를 유지한다는 점이다. |
| 단점 | 데이터에 추가적인 가치를 더해주지 않는다는 점이다. 표현 방식이 바뀌었을 뿐, 데이터의 정보 자체는 동일 그 값이 크고 작은게 의미가 있을 때는 상관 없지만, 순서가 없는 데이터에 적용하게 되면 잘못된 해석을 할 수 있음 |
해당 Feature의 고유값이 많은 경우 Feature를 지나치게 많이 사용한다는 점이다. |
| Pandas | cat.codes | get_dummies |
정의
범주형 데이터를 수치형 데이터로 변환하는 것
종류
label encoder, ordinal encoder, one-hot encoder
LabelEncoder, OrdinalEncoder의 차이?
| Label Encoding | Ordinal Encoding |
| 변수에 순서를 고려하지 않는다. 알파벳 순서 또는 데이터 셋에 등장하는 순서대로 매핑 |
변수에 순서를 고려한다. 변수의 순서 정보를 사용자가 지정할 수 있음 |
| 1차원, y값을 입력 y는 label, 종속변수, target, 정답, 1차원 벡터, 예) 시험의 정답 |
2차원 X값을 입력 X => 독립변수, feature, 2차원 array 형태, 학습할 피쳐 예) 시험의 문제 |
다항식 전개
uniform
균등 분포를 의미한다.
히스토그램을 그렸을 때 어딘가는 많고 적은 데이터가 있다면 그것도 특징이 될 수 있는데 특징이 잘 구분되지 않는다면 power transform 등을 통해 값을 제곱을 해주거나 하면 특징이 좀 더 구분되어 보이기도 합니다.
Feature Scaling
변수 간 구분이 잘 안될 경우 제곱을 해주면 조금 낫다
다항식 전개를 적용할 수 있다
Root를 써서 차항을 놔둘수도 있고 스케일링 할 수 있다
어떤 스케일링 값을 사용할지를 고민해야한다,
루트,로그, 트랜스폼도 해볼 수 있지만 변환이 도움이 될 지를 판단해야 한다
성능이 올라가고 안올라가고는 eda를 통해 확인할 수 있고 점수가 왜 바뀌는지를 알아볼 수 있도록 한다
Tree 알고리즘에서는 사실 피쳐스케일링이 필요하지 않다
변수선택(feature selection)
데이터에 존재하는 Feature들 중 가치가 높은 Feature를 선택, 그렇지 못한 Feature를 버리는 과정
Filtering
분산 기반(Variance Based) Feature Selection
범주형 변수 중 어느 하나의 값에 치중되어 분포되어있지 않은지 확인
Feature가 대부분 같은 값으로 이루어져 있거나 모두 다른 값으로 이루어져 있다면, 그 Feature는 무언가를 예측하는 데 도움이 되지 않을 것 => 제거
상황에 따라 특정 Feature가 변동성이 낮다는 것도 중요한 정보가 될 수 있음
# 범주형 type column만 가져오는 코드
train.select_dtypes(include="O").columns
# 변수형 변수 중에 어느 하나의 값에 치중되어 분포되어있지 않은지 확인합니다.
for col in train.select_dtypes(include="O").columns:
print(train[col].value_counts(1) * 100)
print("-" * 30)상관관계 기반(Correlation Based) Feature Selection
어떤 Feature들은 지나치게 높은 상관관계를 가지고 있을 경우, 머신러닝 모델의 과적합을 막고 학습시간을 줄이기 위해 하나만 채택
corr = train.corr()
# heatmap
mask = np.triu(np.ones_like(corr))
plt.figure(figsize=(20, 15))
sns.heatmap(corr, annot=True, cmap= 'RdYlBu_r', fmt=".2f", mask=mask, vmax=1, vmin=-1
# 의미가 있다고 생각되는 상관계수를 가진 feature만 따로 떼어오기
데이터프레임.corr().loc["feature1", "feature2"]
상관관계와 인과관계 상관계수는 두 변수의 상관관계를 나타내는 지표로 두 변수 간의 직선 관계를 나타내는 것이다.
주의해야할 점은 상관관계가 있다는 것이 인과관계가 있음을 의미하지 않는다는 것이다. 상관관계가 높다는 것은, 원인은 알 수 없지만 서로 상관관계가 높을 뿐이며 하나의 변수가 다른 변수의 원인을 설명하지는 않는다.
추가로, 상관관계를 확인하는데 있어 가장 직관적인 방법은 산점도를 살펴보는 것이다. 산점도가 직선형태로 분포해있다면 상관관계가 높은 것이다.
구분이 잘 안 되는 값에 대해 power transform 을 해주기도 하는데 반대로 너무 차이가 많이 나는 값을 줄일 때 사용할 수 있는 방법?
꼭 정답이 있다기 보다는 EDA를 해보고 어떤 스케일링을 하면 머신러닝 모델이 값을 학습하는데 도움이 될지 고민해 보면 좋습니다.
root, log transform 도 해볼 수 있지만 변환이 정답은 아닙니다.
성능이 올라가고 안 올라가고는 EDA 등을 통해 확인해 보고 왜 점수가 오르고 내리는지 확인해 보는 습관을 길러보세요.
0702
왜도와 첨도
왜도
비대칭도(非對稱度, skewness) 또는 왜도(歪度)는 실수 값 확률 변수의 확률 분포 비대칭성을 나타내는 지표이다. 왜도의 값은 양수나 음수가 될 수 있으며 정의되지 않을 수도 있다.
https://ko.wikipedia.org/wiki/%EB%B9%84%EB%8C%80%EC%B9%AD%EB%8F%84
- 왜도가 음수일 경우에는 확률밀도함수의 왼쪽 부분에 긴 꼬리를 가지며 중앙값을 포함한 자료가 오른쪽에 더 많이 분포해 있다.
- 왜도가 양수일 때는 확률밀도함수의 오른쪽 부분에 긴 꼬리를 가지며 자료가 왼쪽에 더 많이 분포해 있다는 것을 나타낸다.
- 평균과 중앙값이 같으면 왜도는 0이 된다.
첨도
첨도(尖度, 영어: kurtosis 커토시스)는 확률분포의 뾰족한 정도를 나타내는 척도이다. 관측치들이 어느 정도 집중적으로 중심에 몰려 있는가를 측정할 때 사용된다.
https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8F%84
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가깝다.
- 3보다 작을 경우에는(K<3) 정규분포보다 더 완만하게 납작한 분포로 판단할 수 있으며,
- 첨도값이 3보다 큰 양수이면(K>3) 산포는 정규분포보다 더 뾰족한 분포로 생각할 수 있다.
print("왜도(Skewness):", train["SalePrice"].skew())
print("첨도(Kurtosis):", train["SalePrice"].kurtosis())out
- 왜도(Skewness): 1.8828757597682129
- 첨도(Kurtosis): 6.536281860064529
결측치 확인
결측치 수와 비율을 함께 보고 싶다면 합계와 비율을 구해서 concat으로 합친다.
- concat 에서 axis=0 은 행, axis=1은 열을 의미합니다.
# 결측치 확인
isna_sum = df.isnull().sum()
isna_mean = df.isnull().mean()
pd.concat([isna_sum , isna_mean], axis=1).nlargest(10,1)메서드 체이닝을 할 때는 도움말 보기가 잘 동작하지 않기 때문에 도움말을 보기 위해서는 변수에 할당하고 사용하는 것이 좋다.
상관계수
정의
상관 계수는 두 변수의 상관성 표현, 선형 관계를 나타낸다
(상관관계가 있다는 것이 두 변수가 서로 인과관계가 있다는 건 아님 => 상관관계가 높다고 해서 두 변수에서 하나의 변수가 다른 변수의 원인을 설명할 수는 없다)
Scatter Plot
상관관계를 가장 잘 표현하는 직관적인 방법
분포가 직선에 가까울수록 상관관계가 높다고 할 수 있다.
결측치 채우기
- 임의의 값으로 채우기
- 평균, 중앙값으로 채우기
- 제거하기
- 머신러닝 기법으로 채우기
Imputing missing values before building an estimator — scikit-learn documentation - 0 이나 None 으로 채우기
- 단, 범주형 변수는 결측치를 채우지 않으면 따로 인코딩 하지 않는다.
최빈값으로 채우는 방법들
# 최빈값 채우기 - 딕셔너리
mode_dict = df[fill_mode].mode().iloc[0].to_dict()
df[fill_mode] = df[fill_mode].fillna(mode_dict)# 최빈값 채우기 - 시리즈
df[fill_mode] = df[fill_mode].fillna(df[fill_mode].mode().loc[0])# 최빈값 채우기 - 반복문
for col in fill_mode:
df[col] = df[col].fillna(df[col].mode()[0])SQL 로 관리하는 데이터와 파일로 관리하는 데이터는 어떻게 구분해서 관리할까요?
- sql 에 저장하는 데이터는 실시간으로 사용해야 하는 데이터이고
- 파일로 관리하는 데이터는 로그성 데이터 인것 같습니다.
SQL 로 실시간으로 관리할 데이터를 저장한다면 어떤 데이터가 있을까요?
쌓이는 용량이 어느정도냐에 따라 의사결정을 할 수도 있는데 아카이빙할 데이터는 대부분 파일로 저장합니다.
실시간으로 보여주어야 하는 현재 status 값만 DB에 저장해서 사용하기도 합니다.
status값을 업데이트 해서 SQL로 관리하고 아카이빙할 데이터는 파일로 저장합니다.
ex) 로그인, 장바구니, 결제, 회원가입정보, 각종 status 값(게임의 캐릭터 위치, 캐릭터 정보, 게임머니, 캐릭터 가지고 있는 장비 인벤토리 정보)
아카이빙
일반적으로 생각하는 보관과 달리 오래된 데이터나, 사용빈도가 낮은 데이터들을 용량확보나 장기 보관을 위해 따로 데이터를 보관하는것을 의미합니다
데이터를 통해 서비스에 몇 명이 접속하는지, 그분들이 얼마나 많은 상품을 조회하고 얼만큼 구매로 이어지는지 확인할 수 있거든요. 그 과정을 통해 어느 페이지에서 사람들이 이탈하는지도 확인할 수 있었죠. 채용공고에 있었던 어떤 지표로 이 표현을 설명할 수 있을까요?
DAU : Daily Active User 하루에 몇 명이 접속하는지(혹은 로그인 하는지)
AARRR, Funnel : 분석을 통해 얼마나 많은 사람이 와서 물건을 살펴보고 거기서 회원가입 구매전환 친구 추천 혹은 재구매로 이어지는지?
Churn : 얼마나 사람들이 어느 페이지에서 이탈하는지? 퍼널, AARRR 과 함께 볼 수 있는 지표입니다.
AB Testing: 1~2년이 넘는 시간 동안 수백 가지의 노력이 꾸준히 모여서 매달 마주하는 문제를 개선한 것이 결과적으로는 성장의 모멘텀을 만들었다고 생각합니다
그외 기타
train과 test 데이터셋을 합친 경우 장단점
장점 : 전처리를 한 번만 진행
단점 :
1. test에만 등장하는 데이터를 피처에 사용하면 안되는 대회 정책이 있을 때 정책 위반이 될 수 있음
2. 현실세계에서는 불가능한 방법이다.(대회 데이터의 경우 test를 미리 알 수 있지만, 현실에서는 불가능하기때문)
오늘 틀린문제 정리
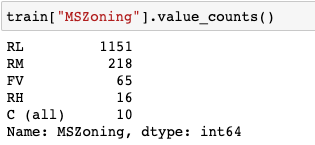
빈도수를 갖는 범주형 변수를 0, 1, 2, 3, 4 의 ordinal 변수로 인코딩하려면
train["MSZoning"].astype("category").cat.codes
빈도수를 갖는 범주형 변수를 One-Hot-Encoding하는 방법
pd.get_dummies(train["MSZoning"])
주어진 다항식의 차수 값에 기반하여 파생변수를 생성할 수 있습니다. 예를 들어 [a, b]가 Feature로 주어질 때 다항식의 최대 차수를 2로 지정했다고 하겠습니다.이 경우 새로 생성될 수 있는 Feature는 [1, a, b, a^2, ab, b^2]입니다.
위에 설명과 같은 특성을 가지며 결과값을 가지는 전처리 방법은 PolynomialFeatures() - 다항회귀
=>데이터를 표현함에 있어 선형이 아닌 곡선으로 나타나는 경우에 사용하는 회귀이다.
다항회귀에서의 항은 차수(degree)를 뜻하는데 말 그대로 차수가 많다는 것을 의미한다.
test 에는 fit을 하지 않습니다.!!!!!
너무 희소한 값을 원핫인코딩할떄 바른 처리방법은
너무 희소한 값을 전처리 하여 피처로 생성하면 연산이 오래 걸리며 오버피팅(과대적합)문제가 발생할 수도 있기떄문에
희소한 값은 기타로 처리한다.
희소한 값을 결측치 처리해서 인코딩 되지 않게 한다.
그러므로 1개만 있는 값이라면 피처로 생성하여 머신러닝 알고리즘이 학습할 수 있게 하지않아야 된다!
참고자료 멋쟁이사자처럼 ais7
https://itstory1592.tistory.com/6
'TIL > 머신러닝' 카테고리의 다른 글
| 11.16 머신러닝 벤츠 그래디언트 부스팅 (선형회귀, 결정 트리 모델 ,엑스트라 트리 모델 (ExtraTree) , Boosting , GBM,LightGBM,XGBoost) (0) | 2022.11.17 |
|---|---|
| 11.15 머신러닝 주택가격, 벤츠 (0) | 2022.11.16 |
| 11/10 머신러닝 주택가격 피처엔지니어링 (0) | 2022.11.10 |
| 11.09 머신러닝 회귀 스케일링 피처 엔지니어링 (1) | 2022.11.10 |
| 11.08 머신러닝 bike log 회귀 (0) | 2022.11.09 |

댓글