1) Cross Validation은 무엇이고 어떻게 해야하나요?
교차검증은 훌련데이터로 모델이 잘 훈련되었는지를 검증데이터를 사용해 검증하는 방법중 하나로
보통 훈련 데이터로 모델을 훈련한 후, 검정 데이터를 사용해 모델이 어떻게 검증되나를 지켜보며 그에 따라 모델의 하이퍼 파라미터를 조정하고 모델의 성능을 올립니다.이때 사용하는 검정 데이터가 한 세트밖에 없다면 검정 데이터로 직접 모델을 훈련하지 않더라도 검정 데이터에 모델이 과적합 될 수 있습니다.
과적합을 피하면서 파라미터를 튜닝하고 일반인 모델을 만들고 더 신뢰성 있는 모델 평가를 진행하기 위해서 사용됩니다

쉽게 말해 데이터를 여러 번 반복해서 나누고 여러 모델을 학습하여 성능을 평가하는 방법입니다
| 장점 | 단점 |
| 특정 데이터셋에 대한 과적합 방지 데이터셋 규모가 적을 시 과소적합 방지 더욱 일반화된 모델 생성 가능 |
모델 훈련 및 평가 소요시간 증가 (반복 학습 횟수 증가) |
이중 가장 많이 사용되는 것은 k겹 교차검증으로 (when k = 5, 즉 5-겹 교차 검증)은 다음과 같이 이루어집니다

- step1) 데이터를 폴드(fold)라는 비슷한 크기의 부분 집합 다섯 개로 나눈다.
- step2) 각 데이터마다 일련의 (총 다섯 가지의)모델을 생성한다.
- 1st 모델 => 테스트 세트 : 1번째 폴드 & 훈련세트 : 나머지 폴드
- 2nd 모델 => 테스트 세트 : 2번째 폴드 & 훈련세트 : 나머지 폴드
- 3rd 모델 => 테스트 세트 : 3번째 폴드 & 훈련세트 : 나머지 폴드
- 4th 모델 => 테스트 세트 : 4번째 폴드 & 훈련세트 : 나머지 폴드
- 5th 모델 => 테스트 세트 : 5번째 폴드 & 훈련세트 : 나머지 폴드
이를 파이썬에서 사이킷런으로 사용하는방법은
cross_validate, cross_val_score를 통해 구현할 수 있고, cross_validate는 각 검증의 결과로 학습시간, 평가시간, 평가점수, 훈련점수를 보여주고 cross_val_score는 각 검증의 평가점수만 보여줍니다
iris데이터셋에 적용한 LogisticRegression을 평가해보았을떄 아래와 같습니다
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
logreg = LogisticRegression()
# scikit-learn 0.22 버전부터 기본적으로 5-겹 교차 검증으로 바뀌었다.
basic_scores = cross_val_score(logreg, iris.data, iris.target)
# 물론 cv 매개변수를 이용하여 k겹의 k를 변경가능하다.
# 하지만, 교차검증에서는 대게 5겹 교차 검증을 자주 사용한다.
cv3_scores = cross_val_score(logreg, iris.data, iris.target, cv = 3)
print('기본 교차 검증 점수 : ', basic_scores)
print('3-겹 교차 검증 점수 : ', cv3_scores)기본 교차 검증 점수 : [0.96666667 1. 0.93333333 0.96666667 1. ]
3-겹 교차 검증 점수 : [0.98 0.96 0.98]
참고문헌
https://jhryu1208.github.io/data/2021/01/24/ML_cross_validation/
2) 회귀 / 분류시 알맞은 metric은 무엇일까요?
# 회귀 문제
회귀 문제에서는 실제 값과 모델이 예측하는 값의 차이에 기반을 둔 metric(평가)을 사용합니다.
대표적으로 RSS(단순 오차 제곱 합), MSE(평균 제곱 오차), MAE(평균 절대값 오차)가 있습니다.
RSS는 예측값과 실제값의 오차의 제곱합,
MSE는 RSS를 데이터의 개수만큼 나눈 값,
MAE는 예측값과 실제값의 오차의 절대값의 평균입니다.
리고 RMSE와 RMAE라는 것도 있는데, 각각 MSE와 MAE에 루트를 씌운 값입니다.
MSE의 경우 오차에 제곱이 되기 때문에 이상치(outlier)를 잡아내는 데 효과적입니다. 틀린 걸 더 많이 틀렸다고 알려주는 것입니다.
MAE의 경우 변동치가 큰 지표와 낮은 지표를 같이 예측하는 데 효과적입니다. 둘 다 가장 간단한 평가 방법으로 직관적인 해석이 가능하지만, 평균을 그대로 이용하기 때문에 데이터의 크기에 의존한다는 단점이 있습니다.
# 분류 문제
분류 문제에서는 어떤 모델이 얼마나 데이터를 클래스에 잘 맞게 분류했느냐를 측정하기 위해서 혼동 행렬(Confusion Matrix)라는 것에서 나오는 지표를 사용합니다. 혼동 행렬은 어떤 데이터에 대해 모델이 예측한 클래스와 실제 클래스가 일치하느냐 아니냐를 따지게 됩니다.
3) 알고 있는 metric에 대해 설명해주세요(ex. RMSE, MAE, recall, precision …)
precision 정밀도!
- 모델의 예측값이 얼마나 정확하게 예측됐는가를 나타내는 지표
- "예"라고 예측했을때의 정답률
예측을 Positive로 한 대상 중 예측값과 실제값이 Positive로 일치한 데이터의 비율을 뜻한다.
Positive 예측 성능을 더욱 정밀하게 측정하기 위한 평가 지표로 양성 예측도라고도 불린다
정밀도와 재현율은 Positive dataset의 예측 성능에 좀 더 초점을 맞춘 평가 지표
정밀도는 FP를 낮추는 데 초점을 맞춘다
실제 음성인 데이터 예측을 양성으로 잘못 판단하면 업무에 큰영향이 발생하는 경우
스팸메일

from sklearn.metrics import precision_score
precision_score(y_test, y_pred)재현율 (recall)
- 실제값 중에서 모델이 검출한 실제값의 비율을 나타내는 지표
- 실제로 병이 있는 전체 중 참 긍정의 비율
- 실제 암환자들이 병원에 갔을때 암환자라고 예측될 확률,조기에 정확하게 발견해서 신속하게 처방하는 것이 올바른 모델
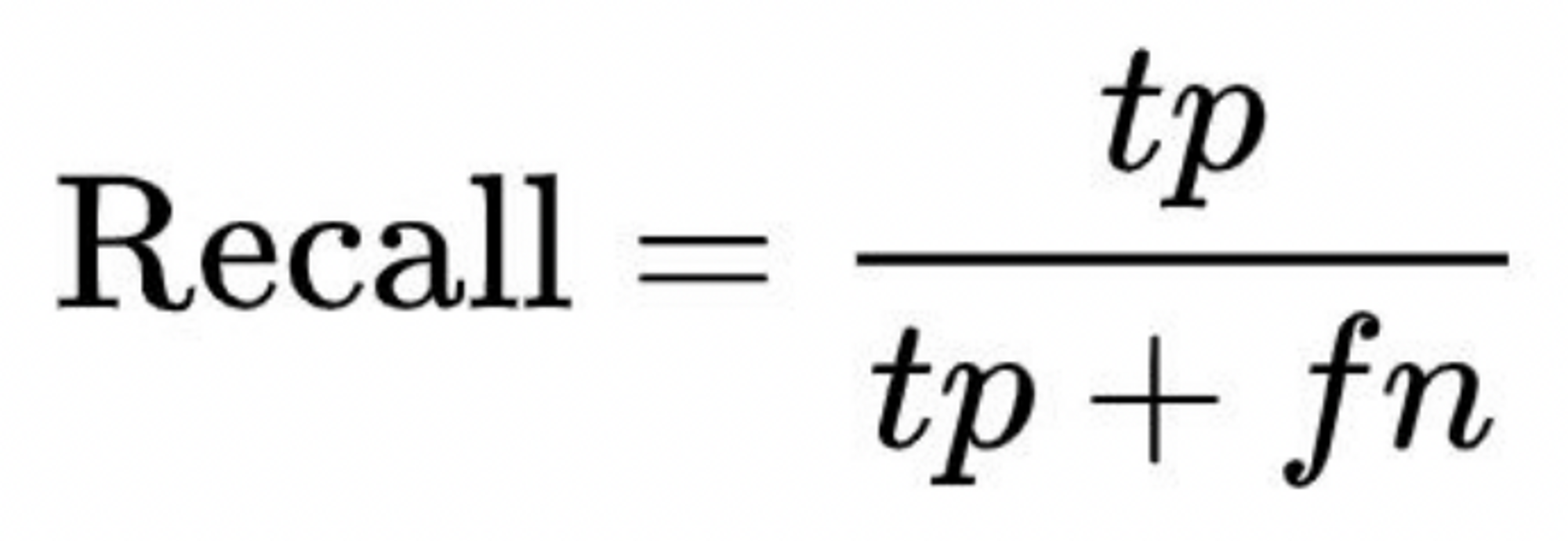
#재현율: metrics.recall_score()
from sklearn.metrics import recall_score
recall_score(df.y, pred)
4) 정규화를 왜 해야할까요? 정규화의 방법은 무엇이 있나요?
우리가 아무리 좋은 데이터를 갖고 있어도 모델에 학습시키기 위해선 스케일링(Scaling)을 해줘야 합니다. 머신러닝 모델은 데이터가 가진 feature(특징)을 뽑아서 학습합니다. 이때 모델이 받아들이는 데이터의 크기가 들쑥날쑥하다면 모델이 데이터를 이상하게 해석할 우려가 있습니다.
변수 스케일링이 중요한이유
- Feature의 범위가 다르면,Feature끼리 비교하기 어려우며 일부 머신러닝 모델에서는 제대로 작동하지 않습니다.
- FeatureScaling이 잘 되어있다면 서로 다른 변수가 있더라도 비교하기 편리합니다
- 비교가 편리하기에 FeatureScaling 없이 작동하는 알고리즘에서 더 빨리 작동합니다
(트리기반 모델은 피처 스케일링이 필요 X - 데이터의 절대적 크기보단 상대적인 크기에 영향 받기에 ) - 또한 머신러닝 성능이 상승합니다
일부 FeatureScaling은 이상치에 대해 강점이 있습니다 (RobustScaler)
| 이름 | 표준화 Normalization- Standardization (Z-scorescaling) |
Min-Maxscaling | Robustscaling |
| 정의 | 평균을 제거하고데이터를 단위 분산에 맞게 조정합니다. |
Feature를 지정된범위로 확장하여 기능을 변환합니다. 기본값은[0,1]입니다. |
중앙값을제거하고 분위수범위(기본값은IQR)에 따라 데이터크기를조정합니다. |
| 장점 | 표준편차가 1이고 0을 중심으로하는 표준정규 분포를 갖도록 조정됩니다 |
편향된 변수에 대한 변환후 변수의 분산을 더 잘 보존합니다. 이상치 제거에 효과적입니다 |
|
| 단점 | 변수가 왜곡되거나 이상치가 있으면 좁은 범위의 관측치를 압축하여 예측력을 손상시킵니다 | 변수가 왜곡되거나 이상치가 있으면 좁은범위의관측치를 압축하여 예측력을 손상시킵니다. |
|
| 수식 | z=(X-X.mean)/std | X_scaled=(X-X.min)/(X.max-X.min) | X_scaled=(X-X.median)/IQR |
| 요약 | ‘평균’을 빼주고 ‘표준편차’로 나눔 | 변수 범위를 0과 1사이로 압축해주는 개념 | 중간값을 빼주고 IQR값으로 나눔 |
| 특징 | 평균 0, 표준편차 1의 특징을 가지고 있음 | 0~1 사이의 값으로 만듬 | 이상치에 영향을 덜 받는다 |
IQR:InterquartileRange로,상위75%와하위25%사이의범위를의미합니다.
{mean : 산술평균, std : 표준편차 ,max : 최대값, min : 최소값,median : 중간값}
5) 부스팅 3대장 모델의 특징
Local Minima와 Global Minima에 대해 설명해주세요.
차원의 저주에 대해 설명해주세요
dimension reduction기법으로 보통 어떤 것들이 있나요?
데이터 분석가에게 ML기술질문으로 자주 등장하는 질문들입니다..! 참고하셔서 공부하시면 좋을듯합니다
'TIL > 프로젝트' 카테고리의 다른 글
| Final Project - 쇼핑몰 리뷰 분석 기반 브랜드 인사이트 도출 (1) | 2023.01.16 |
|---|---|
| cnn미니프로젝트 제출용 질문답변! (0) | 2022.12.11 |

댓글