**Tensorflow 101 - 1. 오리엔테이션 - 링크
딥러닝 = 뉴럴넷 = 인공신경망
이모든말은 인간의 신경을 모방한 이론을 가리키는 같거나 비슷한 말로서
딥러닝이라는 용어를 머신러닝을 대표하는 용어로 사용하게 되었습니다
하지만 이런 표현은 엄연히 다른것입니다
체적인 딥러닝 원리를 몰라도 코드만 작성하면 딥러닝으로 문제를 해결할 수 있는 여러 도구들이 등장했어요. 이것이 라이브러리입니다
대표적인 예로 Tensorflow, Pytotch,Coffe,Theano 가있습니다
이러한 라이브러리(Tensorflow, Pytotch,Coffe,Theano)는딥러닝이라는 같은 알고리즘안에서 만들어진 라이브러로리서로 경쟁관계입니다
이러한 딥러닝 알고리즘 (이론)은 DecisionTree ,RandomForst, KNN SVM와 같은 다른 알고리즘과 경쟁관계입니다
**Tensorflow 101 - 2. 목표와 전략 - 링크
공부전략
- 원인이되는 간단한 코드 작성 ,경험
- 결과로써 코드의 동작과 학습과정을 구경
- 해당코드를 어떻게 이용하면 좋을지 추측
- 원인이되는 또다른 형태의 코드를 작성하고 결과 구경
이런식으로 코드 작성및 결과 반복 구경 하며 딥러닝을 구현하는시간을 가지며
코드와 알고리즘에 익숙해지도록 합니다
(이는 딥러닝으로 구현해보려하는 지도학습의 방법과 같습니다)
**Tensorflow 101 - 3. 지도학습의 빅픽쳐 - 링크
지도학습
예시 레모네이드 가계를 운영한다
1,과거의 데이터 준비
우리의 목표 재료를 버리지않기위해 판매량을 예측하기
2. 모델의 구조를 만듭니다
판매량 = 온도*2
3. 데이터로 모델을 학습(FIT)합니다.
4. 모델을 이용합니다
이를통해 현재온도가 15도라면 판매량은 30개로 예측합니다
**Tensorflow 101 - 4. 환경설정 - Google Colaboratory - 링크
구글 코랩 사용법!
Tensorflow 101 - 5. 표를 다루는 도구 '판다스' - 링크
import pandas ad pd**Tensorflow 101 - 6. 표를 다루는 도구 '판다스' (실습) - 링크
파일 불러오기
pd.read_csv('/경로로/파일명.csv")크기확인하기
print( 데이터.shape() )칼럼 선택하기
데이터 [["칼럼명1","칼럼명2","칼럼명3"]]
칼럼 1개 일시 [] = [ * 1
칼럼 2개 이상 일시 [[ ]] = [ * 2칼럼 이름 출력하기
print( 데이터.columns)맨위, 아래 5개관측치 출력
데이터 .head() 위
데이터.tail() 아래**Tensorflow 101 - 7. 레모네이드 판매 예측- 링크
위에 머신러닝의 과정
1. 과거데이터 준비
레모네이드 = pd.read_csv('kemonade.csv)
독립 = 레모네이드[["온도]]
종속 = 레모네이드[["판매량]]
print(독립.shape, 종속.shape)독립변수와 종속변수를 분리해서 준비합니다
이떄 독립변수와 종속변수의 개수를 확인하는것이 중요한데
이는 모델구조를 만들떄 숫자부분을 맞춰줘야 하기 떄문입니다
2. 모델의 구조 생성
X = tf.keras.layers.Input(shape=[1])
y - tf.keras.layer.Dense(1)(X)
model = tf.keras.models.Model(X,y)
model.compile(loss="mse")[1]의 의미 위 레모네이드 표에서 종속변수의 개수 판매량 1개이기떄문에
3. 데이터로 모델학습
model.fit(독립, 종속, epochs=1000)epochs 학습횟수
4.모델을 이용
print("Predictions: " ,model.predict([15])
**Tensorflow 101 - 8. 손실의 의미 - 링크
model.fit(독립,종속, epochs=10)
loss : 학습이 얼마나 진행되었는지 알려주는 부분
학습이 1회 종료되었을떄마다 얼마나 정답에 가까이 맞추고 있는지를 평하하는 지표입니다
0에 가까이 갈수록 좋습니다
**Tensorflow 101 - 9. 레모네이드 판매 예측 (실습) - 링크
라이브러리 불러오기
라이브러리 불러오기
import tensorflow as tf
import pandas as pd
1. 데이터 준비하기
파일경로 = '<https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/lemonade.csv>'
레모네이드 = pd.read_csv(파일경로)
레모네이드.head()
종속변수, 독립변수
독립 = 레모네이드[['온도']]
종속 = 레모네이드[['판매량']]
print(독립.shape, 종속.shape)
(6, 1) (6, 1)
2. 모델만들기
모델을 만듭니다.
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
(shape=[1]) 독립변수 칼럼갯수 1개
.Dense(1) 종속변수 컬럼개수 1개
model.compile 모델이 학습할 방법
3.모델학습
모델을 학습시킵니다.
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10)
verbose=0 출력을 하지 않도록 설정
⇒ 만번 학습하면서 이는 출력 x / 10번 학습은 출력
Epoch 1/10
1/1 [==============================] - 0s 13ms/step - loss: 0.0011
Epoch 2/10
1/1 [==============================] - 0s 11ms/step - loss: 0.0011
Epoch 3/10
1/1 [==============================] - 0s 9ms/step - loss: 0.0011
Epoch 4/10
1/1 [==============================] - 0s 10ms/step - loss: 0.0011
Epoch 5/10
1/1 [==============================] - 0s 11ms/step - loss: 0.0011
Epoch 6/10
1/1 [==============================] - 0s 8ms/step - loss: 0.0011
Epoch 7/10
1/1 [==============================] - 0s 13ms/step - loss: 0.0011
Epoch 8/10
1/1 [==============================] - 0s 7ms/step - loss: 0.0011
Epoch 9/10
1/1 [==============================] - 0s 6ms/step - loss: 0.0011
Epoch 10/10
1/1 [==============================] - 0s 6ms/step - loss: 0.0011
<keras.callbacks.History at 0x7f9ef30d93d0>
epoch=
맨앞에 epoch= 학습 회수
중간에 ms/step = 학습에 걸린 시간
맨뒤에 losss = 얼마나 정답에 가까이 맞추고 있는지를 평하하는 지표
4.모델이용
모델을 이용합니다.
print(model.predict(독립))
print(model.predict([[15]]))
1/1 [==============================] - 0s 87ms/step
[[40.12165 ]
[42.079784]
[44.037914]
[45.996048]
[47.95418 ]
[49.91231 ]]
1/1 [==============================] - 0s 35ms/step
[[30.330992]]
**Tensorflow 101 - 10. 보스턴집값예측 - 링크
이상치가 있으면 전체 평균이 실제와 괴리가 생기가 됩니다
이에 대안으로 사용하는 값이 바로 중앙값입니다
보스턴 집값예측에서 14번쨰 열인 종속변수인집값을 구하는 식 (나머지 13개 독립변수들이 영향줌)

이를 일일히 계산하는것은 힘든일이니 딥러닝코드로 구현해봅시다!
Tensorflow 101 - 11. 수식과 퍼셉트론 - 링크
Tensorflow 101 - 12. 보스턴 집값 예측 (실습)
1.데이터를 불러옵니다
파일경로 = '<https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv>'
보스턴 = pd.read_csv(파일경로)
print(보스턴.columns)
보스턴.head()
Index(['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat', 'medv'],
dtype='object')
이중
독립변수는 보스턴[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax', 'ptratio', 'b', 'lstat']]
종속변수는 보스턴[[,'medv']]
2. 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
(shape=[13]) = 독립변수의 숫자 13개
'crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax','ptratio', 'b', 'lstat'
Dense(1) 종속변수의 숫자 1개
,'medv'
이러한 모형을 퍼셉트론이라고 합니다
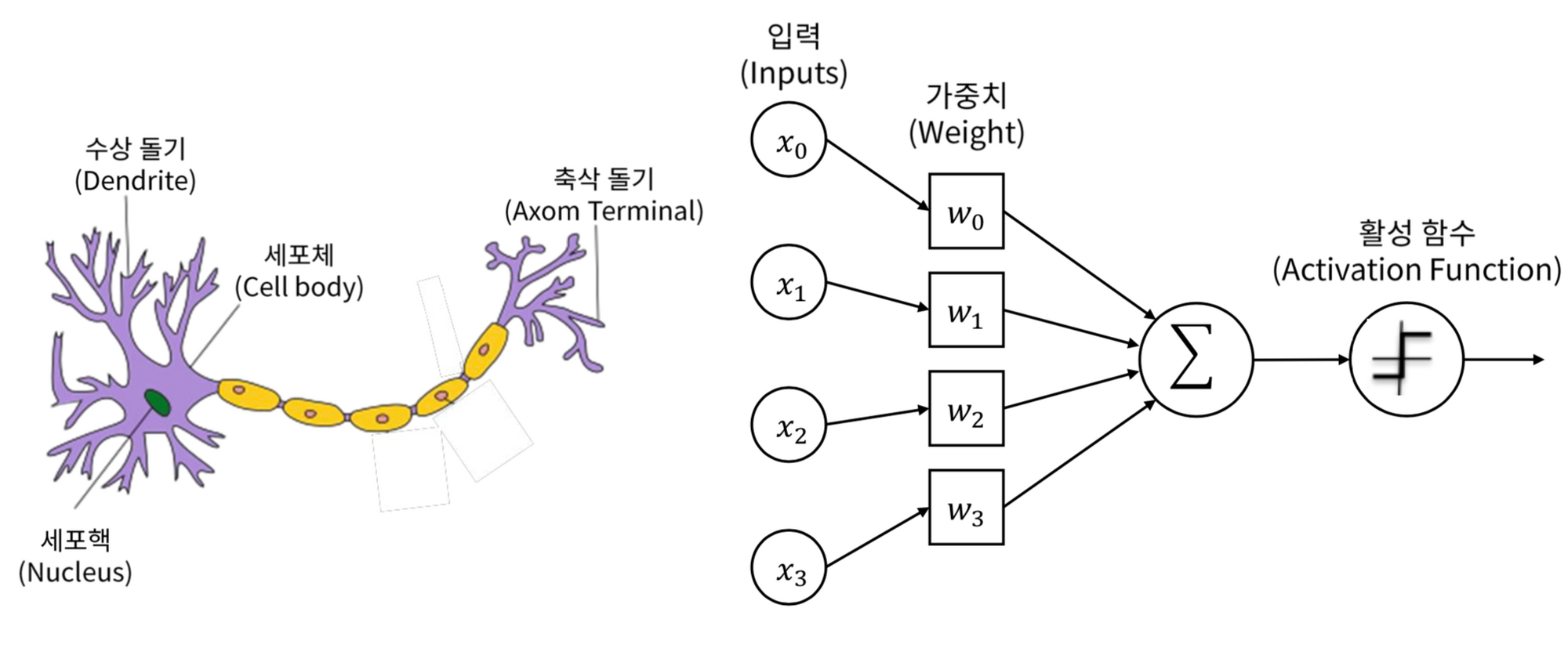
3.데이터로 모델을 학습(FIT)합니다.
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10)
Epoch 1/10
16/16 [==============================] - 0s 2ms/step - loss: 24.2816
Epoch 2/10
16/16 [==============================] - 0s 2ms/step - loss: 24.1009
Epoch 3/10
16/16 [==============================] - 0s 2ms/step - loss: 24.4137
Epoch 4/10
16/16 [==============================] - 0s 2ms/step - loss: 24.6977
Epoch 5/10
16/16 [==============================] - 0s 2ms/step - loss: 24.2158
Epoch 6/10
16/16 [==============================] - 0s 2ms/step - loss: 24.8719
Epoch 7/10
16/16 [==============================] - 0s 2ms/step - loss: 24.6488
Epoch 8/10
16/16 [==============================] - 0s 2ms/step - loss: 23.9153
Epoch 9/10
16/16 [==============================] - 0s 2ms/step - loss: 24.1192
Epoch 10/10
16/16 [==============================] - 0s 2ms/step - loss: 24.6116
<keras.callbacks.History at 0x7f9ef30de110>
4.모델을 이용합니다
print(model.predict(독립[5:10]))
# 종속변수 확인
print(종속[5:10])
1/1 [==============================] - 0s 46ms/step
[[25.764927]
[20.4928 ]
[17.408413]
[ 8.747164]
[17.098217]]
medv
5 28.7
6 22.9
7 27.1
8 16.5
9 18.9
5. 모델의 수식확인
print(model.get_weights())
[array([[-0.08747552],
[ 0.04908248],
[-0.03755538],
[ 2.7610967 ],
[ 1.0676473 ],
[ 5.261094 ],
[-0.01042647],
[-1.0033386 ],
[ 0.1835519 ],
[-0.01070909],
[-0.420604 ],
[ 0.0134167 ],
[-0.46781304]], dtype=float32), array([4.7520556], dtype=float32)]
Tensorflow 101 - 13. 학습의 실제 (with 워크북)
딥러닝 워크북 링크입니다: https://bit.ly/2DEBlPd
딥러닝 워크북은 ("파일" - "사본 만들기")를 하시면 직접 해볼 수 있습니다
Tensorflow 101 - 14. 아이리스 품종 분류 - 링크
Tensorflow 101 - 15. 원핫인코딩
양적데이터 → 회귀 / 범주형 데이터 → 분류
이는 품종이 범주형 데이터이므로 분류로 해야합니다
이때 범주형데이터는 숫자가 아니므로 수식으로 계산할수 없습니다
그러므로 원핫인코딩을 통하여 숫자형태로 만들어줍니다
아이리스 = pd.get_dummies(아이리스)
Tensorflow 101 - 16. softmax
비율로 분류예측 하는 방법에는 sigmoid 와 softmax가 있는데
이중에 softmax를 사용할예정입니다

최종결과를 만들기전에 함수하나가 추가되어 있는 모습인데
회귀모델에서는 없어보엿지만 입력을 그대로 출력하는 idenity함수가 있엇습니다
함수의 출력이 어떤형태로 나가야하는지 조정하는 역활을 하게되고
이런용도로 사용되는 함수들이 activation 함수라고 합니다
Tensorflow 101 - 17. 아이리스 품종 분류 (실습)
- 데이터를 준비합니다
파일경로 = '<https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv>'
아이리스 = pd.read_csv(파일경로)
아이리스.head()
1-1 원핫인코딩을 진행합니다
아이리스 = pd.get_dummies(아이리스)
1-2 종속변수, 독립변수를 분리합니다
print(아이리스.columns)
Index(['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭', '품종_setosa', '품종_versicolor',
'품종_virginica'],
dtype='object')
독립 = 아이리스[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
종속 = 아이리스[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(독립.shape, 종속.shape)
(150, 4) (150, 3)
2. 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[4])
y = tf.keras.layers.Dense(3, activation='softmax')(X)
model = tf.keras.models.Model(X, y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')
activation='softmax softmax적용
metrics='accuracy' = 사람이 보기 좋은 지표인 정확도 추가
3. 데이터로 모델을 학습(FIT)합니다.
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10)
4. 모델을 이용합니다
print(model.predict(독립[:5]))
print(종속[:5])
맨위 5개
1/1 [==============================] - 0s 40ms/step
[[9.9888045e-01 1.1194303e-03 8.6924416e-08]
[9.9593413e-01 4.0650615e-03 8.6360967e-07]
[9.9796152e-01 2.0381443e-03 3.1603085e-07]
[9.9451315e-01 5.4855016e-03 1.2984966e-06]
[9.9905699e-01 9.4293884e-04 6.5486795e-08]]
품종_setosa 품종_versicolor 품종_virginica
0 1 0 0
1 1 0 0
2 1 0 0
3 1 0 0
4 1 0 0
print(model.predict(독립[-5:]))
print(종속[-5:])
맨마지막 5개 -슬라이싱이용
1/1 [==============================] - 0s 85ms/step
[[8.4733659e-07 8.0596462e-02 9.1940266e-01]
[1.8923764e-06 1.4743319e-01 8.5256493e-01]
[3.8392782e-06 2.0760971e-01 7.9238647e-01]
[9.4461922e-07 9.6634366e-02 9.0336466e-01]
[8.7661529e-06 3.0645302e-01 6.9353825e-01]]
품종_setosa 품종_versicolor 품종_virginica
145 0 0 1
146 0 0 1
147 0 0 1
148 0 0 1
149 0 0 1
5.학습한 가중치 확인
print(model.get_weights())
[array([[ 1.340472 , 0.72075814, 0.08018463],
[ 2.6712413 , 0.3340035 , -1.4227159 ],
[-2.9053495 , 0.58382034, 1.5004412 ],
[-3.4893618 , -1.1937621 , 2.8828862 ]], dtype=float32), array([ 1.6990361, 0.9021373, -1.2443118], dtype=float32)]
Tensorflow 101 - 18. 히든레이어 - 링크
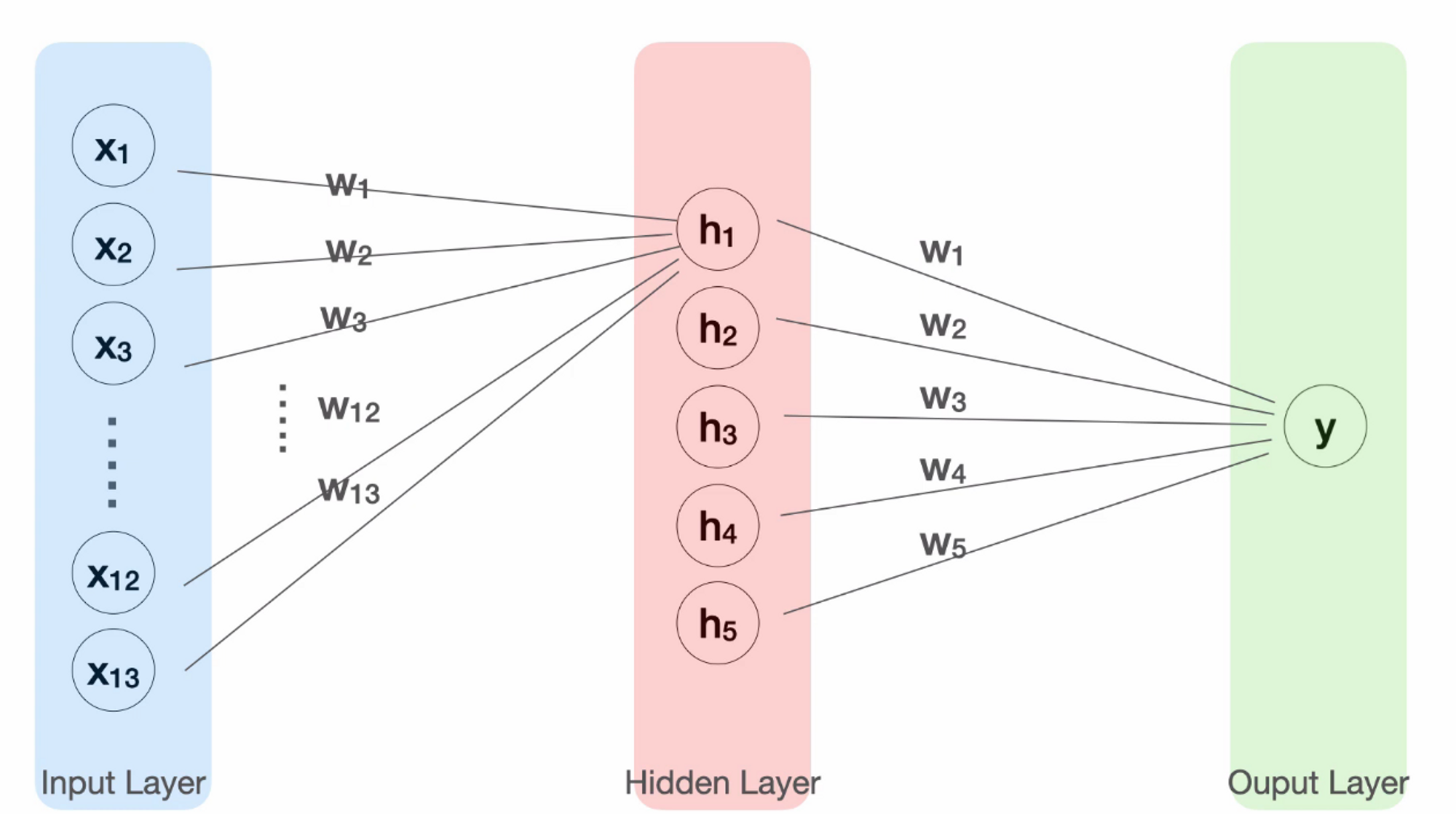
X 인풋과 y 아웃풋 사이에 추가되는 것으로
# 2. 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
h = tf.keras.layers.Dense(10, activation='swish')(X)
y = tf.keras.layers.Dense(1)(h)
model = tf.keras.models.Model(X, y)
model.compile(loss='mse')
이떄 히든레이어를 사용시 y는 X가 아닌 h를 넣어줘야합니다
히든레이어의 활성화 함수는 activation='swish' 를 사용합니다
# 2-1 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
h = tf.keras.layers.Dense(5, activation='swish')(X)
h = tf.keras.layers.Dense(3, activation='swish')(h)
h = tf.keras.layers.Dense(3, activation='swish')(h)
y = tf.keras.layers.Dense(1)(h)
model = tf.keras.models.Model(X, y)
model.compile(loss='mse')
히든레이어는 다층으로도 쌓아갈수 있습니다
Tensorflow 101 - 19. 히든레이어 (실습)
A . 보스턴
모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(10, activation='swish')(X)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 모델 구조 확인
model.summary()
Model: "model_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) [(None, 13)] 0
dense_5 (Dense) (None, 10) 140
dense_6 (Dense) (None, 1) 11
=================================================================
Total params: 151
Trainable params: 151
Non-trainable params: 0
_________________________________________________________________
Param - 컴퓨터가 학습하는 가중치 개수
(None, 10) - 10개의 출력 (10개의 수식)
일력 -13개니 항이 13개 bias 1개해서 수식마다 14개 의 가중치가 필요합니다
고로 가중치는 140개
(None, 1) = 10개의 입력을 받아서 1개의 출력
Param 11 - 수식항이 10개에 bias 1개로 11개의 가중치를 찾는다
print(model.predict(독립[:5]))
print(종속[:5])
1/1 [==============================] - 0s 114ms/step
[[27.17023 ]
[27.77638 ]
[29.588257]
[31.340603]
[30.978283]]
medv
0 24.0
1 21.6
2 34.7
3 33.4
4 36.2
# 모델의 수식 확인
print(model.get_weights())
[array([[ 0.07451724, 0.0374129 , -0.48813796, 0.5360581 , -0.3472171 ,
0.26570413, 0.37851793, 0.0601074 , -0.18969531, 0.23741674],
[-0.07886989, 0.27593902, 0.1129443 , 0.11365926, 0.36139646,
-0.26505026, 0.34563124, -0.41721576, 0.39669132, 0.01023602],
[-0.3608811 , -0.46907023, 0.08695507, 0.15499887, 0.15175389,
0.4506661 , -0.15674955, 0.5607524 , -0.08023136, 0.49969846],
[-0.05545024, -0.14709558, 0.29749078, -1.1239942 , -0.31142098,
0.3224185 , 0.56113905, 0.46575877, 0.71584415, -0.34506574],
[-0.41095924, -0.3489058 , -0.23740178, -0.39781222, -0.52953094,
-0.24236645, 0.09364283, -0.12810107, 0.5474038 , -0.47104612],
[-0.24283516, -0.0731224 , 0.16177315, -1.017139 , -0.55802745,
-0.4772182 , -0.02044729, -0.49680746, 1.1437535 , 0.01847261],
[ 0.0252977 , 0.04946449, -0.23007956, -0.41285333, 0.3786443 ,
-0.42955485, 0.49394172, 0.17639987, -0.03333566, 0.5006061 ],
[ 0.45067462, 0.15054835, -0.33902663, -0.3371131 , -0.04288997,
-0.21670115, 0.05312374, 0.0174383 , 0.32473853, -0.44385964],
[-0.23346624, 0.3889577 , 0.04176617, -0.60101616, 0.06736487,
0.04613215, 0.33132756, -0.43382096, -0.0029233 , 0.07500637],
[-0.2253141 , -0.19318223, -0.5063432 , 0.2671286 , -0.24958085,
0.03004601, -0.4251262 , -0.26968518, 0.16062915, -0.29760122],
[-0.2940565 , 0.01949803, 0.21385145, -0.5773164 , 0.4358774 ,
0.16499549, -0.3964595 , -0.24326433, 0.65577465, -0.4175499 ],
[ 0.16229668, 0.08602092, -0.11123121, -0.00739085, 0.10428539,
-0.27578777, 0.252687 , 0.17342943, 0.14027034, -0.35078007],
[ 0.47988567, -0.06879715, 0.08939934, 1.000832 , 0.69541895,
-0.17586061, -0.12574947, 0.13180305, -0.53149056, 0.17306995]],
dtype=float32), array([-0.19998181, -0.15772593, 0. , -0.44087547, -0.04445587,
-0.03268292, 0.07810342, -0.06040015, 0.4547858 , 0. ],
dtype=float32), array([[-0.13912824],
[-0.1026617 ],
[-0.5187744 ],
[-0.16619267],
[-0.5165918 ],
[-0.9369006 ],
[ 0.63834363],
[-0.14856923],
[ 0.25328615],
[-0.17816299]], dtype=float32), array([0.45052037], dtype=float32)]
B. 아이리스
X = tf.keras.layers.Input(shape=[4])
H = tf.keras.layers.Dense(8, activation="swish")(X)
H = tf.keras.layers.Dense(8, activation="swish")(H)
H = tf.keras.layers.Dense(8, activation="swish")(H)
Y = tf.keras.layers.Dense(3, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')
model.summary()
Model: "model_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_7 (InputLayer) [(None, 4)] 0
dense_11 (Dense) (None, 8) 40
dense_12 (Dense) (None, 8) 72
dense_13 (Dense) (None, 8) 72
dense_14 (Dense) (None, 3) 27
=================================================================
Total params: 211
Trainable params: 211
Non-trainable params: 0
_________________________________________________________________
print(model.predict(독립[:5]))
print(종속[:5])
1/1 [==============================] - 0s 48ms/step
[[9.9944371e-01 5.5613439e-04 1.0738166e-07]
[9.9875224e-01 1.2471527e-03 6.1315239e-07]
[9.9889511e-01 1.1045573e-03 4.0288208e-07]
[9.9711835e-01 2.8806934e-03 9.5060511e-07]
[9.9937493e-01 6.2500732e-04 9.7224444e-08]]
품종_setosa 품종_versicolor 품종_virginica
0 1 0 0
1 1 0 0
2 1 0 0
3 1 0 0
4 1 0 0
Tensorflow 101 - 20. 데이터를 위한 팁 (appendix 1) - 링크
변수의 타입 확인
데이터.dtypes
변수를 범주형으로 변경:
데이터 [”칼럼명”].astype(”category”)
변수를 수치형으로 변경
데이터 [”칼럼명”].astype(”int”)
데이터 [”칼럼명”].astype(”float”)
na값의 처리
nan갯수체크
데이터.isna().sum()
nan값 채우기
데이터[”칼럼명”].fillna(특정숫자)
**Tensorflow 101 - 21. 모델을 위한 팁 (appendix 2) - 링크
사용할 레이더
tf.keras.layers.BatchNormalization()
는 dense later와 activation layer사이에 넣어주는게 효과가 좋다
tf.keras.layers.Activation(”swish”)
# 2. 모델의 구조를 BatchNormalization layer를 사용하여 만든다.
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 2. 모델의 구조를 BatchNormalization layer를 사용하여 만든다.
X = tf.keras.layers.Input(shape=[4])
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(3, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')
**Tensorflow 101 - 22. 수업을 마치며 - 링크
이러한 과정의 이해를 마쳤습니다
표형태의 데이터를 가지고 딥러닝 모델을 만들고 학습을 시키는데 필요한 최소한의 지식을 배웠습니다
print(model.get_weights())
[array([[ 1.340472 , 0.72075814, 0.08018463],
[ 2.6712413 , 0.3340035 , -1.4227159 ],
[-2.9053495 , 0.58382034, 1.5004412 ],
[-3.4893618 , -1.1937621 , 2.8828862 ]], dtype=float32), array([ 1.6990361, 0.9021373, -1.2443118], dtype=float32)]
**Tensorflow 101 - 18. 히든레이어 - 링크
X 인풋과 y 아웃풋 사이에 추가되는 것으로
# 2. 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
h = tf.keras.layers.Dense(10, activation='swish')(X)
y = tf.keras.layers.Dense(1)(h)
model = tf.keras.models.Model(X, y)
model.compile(loss='mse')
이떄 히든레이어를 사용시 y는 X가 아닌 h를 넣어줘야합니다
히든레이어의 활성화 함수는 activation='swish' 를 사용합니다
# 2-1 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
h = tf.keras.layers.Dense(5, activation='swish')(X)
h = tf.keras.layers.Dense(3, activation='swish')(h)
h = tf.keras.layers.Dense(3, activation='swish')(h)
y = tf.keras.layers.Dense(1)(h)
model = tf.keras.models.Model(X, y)
model.compile(loss='mse')
히든레이어는 다층으로도 쌓아갈수 있습니다
Tensorflow 101 - 19. 히든레이어 (실습)
A . 보스턴
모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(10, activation='swish')(X)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 모델 구조 확인
model.summary()
Model: "model_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) [(None, 13)] 0
dense_5 (Dense) (None, 10) 140
dense_6 (Dense) (None, 1) 11
=================================================================
Total params: 151
Trainable params: 151
Non-trainable params: 0
_________________________________________________________________
Param - 컴퓨터가 학습하는 가중치 개수
(None, 10) - 10개의 출력 (10개의 수식)
일력 -13개니 항이 13개 bias 1개해서 수식마다 14개 의 가중치가 필요합니다
고로 가중치는 140개
(None, 1) = 10개의 입력을 받아서 1개의 출력
Param 11 - 수식항이 10개에 bias 1개로 11개의 가중치를 찾는다
print(model.predict(독립[:5]))
print(종속[:5])
1/1 [==============================] - 0s 114ms/step
[[27.17023 ]
[27.77638 ]
[29.588257]
[31.340603]
[30.978283]]
medv
0 24.0
1 21.6
2 34.7
3 33.4
4 36.2
# 모델의 수식 확인
print(model.get_weights())
[array([[ 0.07451724, 0.0374129 , -0.48813796, 0.5360581 , -0.3472171 ,
0.26570413, 0.37851793, 0.0601074 , -0.18969531, 0.23741674],
[-0.07886989, 0.27593902, 0.1129443 , 0.11365926, 0.36139646,
-0.26505026, 0.34563124, -0.41721576, 0.39669132, 0.01023602],
[-0.3608811 , -0.46907023, 0.08695507, 0.15499887, 0.15175389,
0.4506661 , -0.15674955, 0.5607524 , -0.08023136, 0.49969846],
[-0.05545024, -0.14709558, 0.29749078, -1.1239942 , -0.31142098,
0.3224185 , 0.56113905, 0.46575877, 0.71584415, -0.34506574],
[-0.41095924, -0.3489058 , -0.23740178, -0.39781222, -0.52953094,
-0.24236645, 0.09364283, -0.12810107, 0.5474038 , -0.47104612],
[-0.24283516, -0.0731224 , 0.16177315, -1.017139 , -0.55802745,
-0.4772182 , -0.02044729, -0.49680746, 1.1437535 , 0.01847261],
[ 0.0252977 , 0.04946449, -0.23007956, -0.41285333, 0.3786443 ,
-0.42955485, 0.49394172, 0.17639987, -0.03333566, 0.5006061 ],
[ 0.45067462, 0.15054835, -0.33902663, -0.3371131 , -0.04288997,
-0.21670115, 0.05312374, 0.0174383 , 0.32473853, -0.44385964],
[-0.23346624, 0.3889577 , 0.04176617, -0.60101616, 0.06736487,
0.04613215, 0.33132756, -0.43382096, -0.0029233 , 0.07500637],
[-0.2253141 , -0.19318223, -0.5063432 , 0.2671286 , -0.24958085,
0.03004601, -0.4251262 , -0.26968518, 0.16062915, -0.29760122],
[-0.2940565 , 0.01949803, 0.21385145, -0.5773164 , 0.4358774 ,
0.16499549, -0.3964595 , -0.24326433, 0.65577465, -0.4175499 ],
[ 0.16229668, 0.08602092, -0.11123121, -0.00739085, 0.10428539,
-0.27578777, 0.252687 , 0.17342943, 0.14027034, -0.35078007],
[ 0.47988567, -0.06879715, 0.08939934, 1.000832 , 0.69541895,
-0.17586061, -0.12574947, 0.13180305, -0.53149056, 0.17306995]],
dtype=float32), array([-0.19998181, -0.15772593, 0. , -0.44087547, -0.04445587,
-0.03268292, 0.07810342, -0.06040015, 0.4547858 , 0. ],
dtype=float32), array([[-0.13912824],
[-0.1026617 ],
[-0.5187744 ],
[-0.16619267],
[-0.5165918 ],
[-0.9369006 ],
[ 0.63834363],
[-0.14856923],
[ 0.25328615],
[-0.17816299]], dtype=float32), array([0.45052037], dtype=float32)]
B. 아이리스
X = tf.keras.layers.Input(shape=[4])
H = tf.keras.layers.Dense(8, activation="swish")(X)
H = tf.keras.layers.Dense(8, activation="swish")(H)
H = tf.keras.layers.Dense(8, activation="swish")(H)
Y = tf.keras.layers.Dense(3, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')
model.summary()
Model: "model_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_7 (InputLayer) [(None, 4)] 0
dense_11 (Dense) (None, 8) 40
dense_12 (Dense) (None, 8) 72
dense_13 (Dense) (None, 8) 72
dense_14 (Dense) (None, 3) 27
=================================================================
Total params: 211
Trainable params: 211
Non-trainable params: 0
_________________________________________________________________
print(model.predict(독립[:5]))
print(종속[:5])
1/1 [==============================] - 0s 48ms/step
[[9.9944371e-01 5.5613439e-04 1.0738166e-07]
[9.9875224e-01 1.2471527e-03 6.1315239e-07]
[9.9889511e-01 1.1045573e-03 4.0288208e-07]
[9.9711835e-01 2.8806934e-03 9.5060511e-07]
[9.9937493e-01 6.2500732e-04 9.7224444e-08]]
품종_setosa 품종_versicolor 품종_virginica
0 1 0 0
1 1 0 0
2 1 0 0
3 1 0 0
4 1 0 0
Tensorflow 101 - 20. 데이터를 위한 팁 (appendix 1) - 링크
- 변수의 타입 확인
- 데이터.dtypes
- 변수를 범주형으로 변경:
- 데이터 [”칼럼명”].astype(”category”)
- 변수를 수치형으로 변경
- 데이터 [”칼럼명”].astype(”int”)
- 데이터 [”칼럼명”].astype(”float”)
- na값의 처리
- nan갯수체크
- 데이터.isna().sum()
- nan갯수체크
- nan값 채우기
- 데이터[”칼럼명”].fillna(특정숫자)
Tensorflow 101 - 21. 모델을 위한 팁 (appendix 2) - 링크
사용할 레이더
tf.keras.layers.BatchNormalization()
는 dense later와 activation layer사이에 넣어주는게 효과가 좋다
tf.keras.layers.Activation(”swish”)
# 2. 모델의 구조를 BatchNormalization layer를 사용하여 만든다.
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 2. 모델의 구조를 BatchNormalization layer를 사용하여 만든다.
X = tf.keras.layers.Input(shape=[4])
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(3, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')
**Tensorflow 101 - 22. 수업을 마치며 - 링크

이러한 과정의 이해를 마쳤습니다
표형태의 데이터를 가지고 딥러닝 모델을 만들고 학습을 시키는데 필요한 최소한의 지식을 배웠습니다
'TIL > 딥러닝' 카테고리의 다른 글
| 12/13 화 NLP 자연어 전처리 (1) | 2022.12.14 |
|---|---|
| 12월 12일 NLP BOW TF-IDF (0) | 2022.12.13 |
| 12월 6일 딥러닝 말라리아 CNN 분류 , cnn개념 용어 정리 !!! (1) | 2022.12.08 |
| 12월 5일 딥러닝 CNN 기초 (0) | 2022.12.06 |
| 딥러닝과 머신러닝의 차이/ 활성화함수/ 기울기소실문제 (0) | 2022.12.03 |

댓글