| Tensorflow를 사용한 CNN 모델 Overview | |
| 층 구성 tf.keras.sequential() |
tf.keras.models.Sequential([ tf.keras.Conv2D(input_shape=()),# 입력층 tf.keras.MaxPooling2D(), tf.keras.layers.Flatten(),# 은닉층 tf.keras.layers.Dense() # 출력층 ]) |
| 활성화 함수 (activation) |
- ‘linear’ : 그대로 출력 - ‘relu’ : 은닉층에 주로 사용 - ‘sigmoid’ : 이진 분류 문제(출력층) - ‘softmax’ :다중 클래스 분류 문제(출력층) |
| 컴파일 model.compile() |
model.compile(optimizer, loss, metrics) - optimizer: SGD, RMSprop, Adam - loss 회귀: MSE, MSE, 분류:binary_crossentropy (이진분류) categorical_crossentropy (다중분류: 원핫인코딩) sparse_categorical_crossentropy (다중분류: 정수형태) - metrics: 분류 : accuracy, AUC 회귀 : MAE, MSE |
| 요약 model.summary() |
model.summary() - Layer (type) - Output Shape - Param |
| 학습 model.fit() |
model.fit(X_train, y_train, epochs) |
| 예측 model.predict() |
model.predict(x_test) |
| 평가 model.evaluate() |
model.evaluate(X_test, y_test, batch_size) tf.keras.callbacks.history() - acc : 훈련 정확도 - val_acc : 검증 정확도 - loss : 훈련 손실값 - val_loss : 검증 손실값 |
| CNN의 핵심 요소 | |
| 필터 | 각 레이어의 입출력 데이터의 형상 유지, 복수의 필터로 이미지의 특징 추출 및 학습 |
| 합성곱층 | 입력 데이터의 특징을 추출하여 특징들의 패턴을 파악, 이미지의 공간 정보를 유지하면서 특징을 인식 |
| 풀링층 | 추출한 이미지의 특징을 모으고 강화하는 레이어 |
| CNN의 영역 | |
| 특징 추출영역 | 합성곱층(필터적용, 활성화 함수 반영)과 풀링층(선택적)을 여러 겹 쌓은 형태 - Convolution Layer는 입력 데이터에 필터를 적용 후 활성화 함수를 반영하는 필수 요소 - Pooling Layer는 추출한 특징을 강화하며 선택적인 레이어 |
| 클래스 분류 영역 | CNN 마지막 부분에는 이미지 분류를 위한 완전 연결 계층(FC) 추가 - Fully Connected Layer는 CNN 마지막부분으로 이미지 분류를 위한 레이어 |
| cnn의 주요 용어 정리 | |
| 채널 (Channel) |
이미지 픽셀 하나하라는 실수이며 / 높이 , 폭 ,채널 -input_shape=() 컬러 사진은 RGB= 3개 실수 표현 / 흑백사신은 2차원 데이터로 1개채널로 구성 입력데이터는 한개 이상 필터가 적용되며 1개 필터는 특징맵(Feature Map)의 채널 합성곱층(Convolution Layer)에 n개의 필터가 적용된다면 출력 데이터는 n개의 채널을 생성 |
| 합성곱 (Convolution) |
데이터의 특징을 추출하는 과정 필터를 사용하여 인접 데이터를 조사, 특징 파악 하여 한장으로 도출 추상화 하나의 압축과정으로 파라미터의 개수를 효과적으로 축소 (EX 고양이사진에서 고양이의 눈 , 귀, 입을 추상화) 구조 필터= 특징(feature)이 데이터에 있는지 없는지 검출하여 가중치 부여(만약 데이터가 있다면 1, 없다면 0) 활성화 함수 = 특징 유무를 수치화하기 위해 비선형 값으로 바꿔주는 함수(필터로 분류된 데이터가 대상) |
| CNN 과정 |
|
| 1. 총구성 keras.sequential 1-1 모델 만들기(분류) |
|
| model = models.Sequential([ tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), # 첫레이어 input_shape설정 tf.keras.layers.MaxPooling2D((2, 2)), # pool_size 는 윈도우의 크기를 의미하며 수직, 수평 축소 비율을 지정 tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), # 필터의 수=64, 커널사이즈=(3,3) tf.keras.layers.MaxPooling2D((2, 2)), # (2, 2)이면 출력 영상 크기는 입력 영상 크기의 반으로 줄어듬 tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), # 필터의 수=64, 커널사이즈=(3,3) tf.keras.layers.Flatten(), # 추출된 특징을 전결합층에 전달하기 위해 배열 형태로 flat(흑백2D or 컬러3D → 1D) tf.keras.layers.Dense(64, activation='relu'), # 클래스 분류를 위한 완전 연결 계층(FC) 추가 tf.keras.layers.Dropout(0.2), # 과대적합을 피하기 위해 드롭아웃을 레이어에 적용하여 20%를 무작위로 드롭아웃 # 0.1, 0.2, 0.4 등의 값을 입력하면 해당 층에서 출력 단위의 10%, 20% 또는 40%를 임의로 제거 tf.keras.layers.Dense(10, activation='softmax') ]) # 10개의 노드를 소프트맥스 함수로 확률 반환(전체 합=1) |
|
| tf.keras.layers.Conv2D( filters [컨볼루션 필터의 수 >> 필터 수 = 특징맵 수] , kernel_size [컨볼루션 커널의 (행, 열) >> 필터 사이즈] , strides=(1, 1), padding='valid'[경계 처리 방법] - ‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다. - ‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다. , input_shape=(28, 28, 1)[모델에서 첫 레이어일 때만 정의하면 됨 (batchSize, height, width, channels)], data_format=None, dilation_rate=(1, 1), groups=1, activation=None[활성화 함수 설정합니다] - ‘linear’ : 디폴트 값, 입력뉴런과 가중치로 계산된 결과값이 그대로 출력 - ‘relu’ : rectifier 함수, 은닉층에 주로 사용 - ‘sigmoid’ : 시그모이드 함수, 이진 분류 문제에서 출력층에 주로 사용 - ‘softmax’ : 소프트맥스 함수, 다중 클래스 분류 문제에서 출력층에 주로 사용 , use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, **kwargs) |
|
| CNN 과정 - MaxPool2D | |
| 컨볼루션 레이어의 출력 이미지에서 주요값만 뽑아 크기가 작은 출력 영상을 생성 지역적인 사소한 변화가 영향을 미치지 않도록 주의 필요 tf.keras.layers.Flatten( data_format=None, **kwargs) data_format : 문자열, channels_last(기본값) 또는 channels_first. 입력에서 차원의 순서 |
|
| CNN 과정 - Flatten | |
| CNN에서 컨볼루션 레이어나 맥스풀링 레이어를 반복적으로 거치면 주요 특징만 추출(흑백2차원 자료)되고, 추출된 주요 특징은 전결합층에 전달되어 학습될 예정. 전결합층에 전달하기 위해선 1차원 자료로 변경 필요 |
|
| CNN 과정 - Dense | |
| tf.keras.layers.Dense( units [ units : 출력 값의 크기] , activation=None [activation : 활성화 함수], use_bias=True [편향(b)을 사용할지 여부] , kernel_initializer='glorot_uniform' [가중치(W) 초기화 함수] , bias_initializer='zeros' [편향 초기화 함수] , kernel_regularizer=None [가중치 정규화 방법], bias_regularizer=None [편향 정규화 방법], activity_regularizer=None [출력 값 정규화 방법], kernel_constraint=None [가중치에 적용되는 부가적인 제약 함수], bias_constraint=None [편향에 적용되는 부가적인 제약 함수] , **kwargs) * 출력층 회귀의 출력 >> tf.keras.layers.Dense(1) 이진분류의 출력 >> tf.keras.layers.Dense(1,activation=’sigmoid’) 다중클래스 출력 >> tf.keras.layers.Dense(n,activation=’softmax’) |
| 2. 컴파일 model.complie() |
| model.compile(optimizer='adam', # 옵티마이저: 손실 함수의 값을 가능한 낮추는 매개변수(가중치와 편향) 탐색 훈련과정을 설정 , 최적화 알고리즘 설정 의미 (adam, sgd, rmsprop, adagrad 등) loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 손실함수 설정 - binary_crossentropy: 이진분류 - categorical_crossentropy: label(target)이 one-hot vector - sparse_categorical_crossentropy: label(target)이 정수형태 metrics=['accuracy']) # 각 훈련 epoch에 대한 훈련 및 검증 정확성을 보려면 metrics 인수를 전달 훈련 및 테스트 중에 모델이 평가할 메트릭 목록 - 분류에서는 accuracy - 회귀에서는 mse, rmse, r2, mae, mspe, mape, msle 등 - 사용자가 메트릭을 정의해서 사용 가능 |
| 2-1 분류 model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) |
| 2-2 회귀 model.compile(optimizer='rmsprop', loss='mse', metrics=['mae','mse']) |
| 학습 model.fit() |
model.fit(train_images, train_labels, epochs=5, batch_size=128)
|
relu를 통과한 피처맵을 무엇이라 부를까요?

액티베이션맵
MaxPooling 을 하게 되면 어떻게 될까요?

가로세로의 길이가 줄고, 일정한 영역에서 가장 큰 값만 남습니다
Pooling
=> 이미지 크기를 줄여 계산을 효율적으로 하고 데이터를 압축하는 효과( 추상화)가 있기 때문에 오버피팅을 방지해 주기도 합니다.
Max(MaxPooling 은 가장 큰 값을 반환)
Average(AveragePooling 은 평균 값 반환)
Min(MinPooling 은 최솟값 반환) 등 여러 방법이 있는데,
보통 MaxPooling 을 주로 사용합니다. 흑백이미지에서는 MinPooling 을 사용하기도 합니다.
stride 값을 조정할 수 있습니다.
마지막에 softmax 는 어떻게 결과를 처리할까요?

출력값이 출력값이 n개의 확률로 나오고, n개의 확률값의 합이 1 입니다
멀티클래스 분류에 주로 사용합니다. 가장 큰 확률값을 클래스의 답으로 사용합니다.
가장 큰 확률값을 찾는 방법은 무엇일까요?
np.argmax()
np.argmax() 를 사용하면 가장 큰 확률값에 대한 인덱스를 반환합니다. 가장 큰 값의 인덱스를 답으로 사용합니다.
binary 분류에는 출력 activation으로 무엇을 사용할까요?
시그모이드 sigmoid
0~1 사이의 확률값을 반환하며 임계값(보통은 0.5)을 기준으로 분류합니다
https://colab.research.google.com/drive/1okXxiVGuAQlsboyhTbqEIX5FL9OleBws#scrollTo=DPHx8-t-VrVo
classification.ipynb

튤립이 너무 멀리잇고튤린아닌부분이 많아서 학습에 문제가 생길수있다
이미지데이터를 분류할때도 전처리가 중요합니다. 좋은 데이터를 넣어주어야 학습결과가 좋게 나옵니다.
또한 이미지 사이즈가 다 다르면 계산을 할 수 없기 때문에
사이즈도 맞춰줄 필요가 있습니다.
=> 그럼 이 때 어떤 사이즈로 만들어주는게 좋을까요?
PIL , OpenCV 등을 내부에서 사용하고 있는데 우리가 포토샵에서 이미지 사이즈 줄이는 것 처럼 이미지 사이즈를 조정해 줍니다.
그럼 이 때 어떤 사이즈로 만들어주는게 좋을까요?
PIL , OpenCV 등을 내부에서 사용하고 있는데 우리가 포토샵에서 이미지 사이즈 줄이는 것 처럼 이미지 사이즈를 조정해 줍니다.
이미지 사이즈
| 이미지 사이즈변경의 차이 | |
| 작게 만들면 | 크게 만들면 |
|
|
| 그럼 각각 장단점이 있는데 뭐를 써야할까요 대체적으로 계산편의를 위해서 보통 정사각형으로 만들어줍니다 |
|
이미지 사이즈별 단점을 convolution 구조에서 다양한 설정 방법으로 보완 가능한가요?
이미지 사이즈도 하이퍼파라미터처럼 조정을 하면 성능이 달라지고 Conv, Pooling 도 성능에 영향을 줍니다. 어떤식으로 레이어를 구성하냐에 따라 보완이 가능하기도 합니다.

이 이미지에서 모델이 학습했을 때 오버피팅이 되거나 혼란이 있을수 있는 게 있다면 어떤게 있을까요?
filters : 컨볼루션 필터의 수 == 특징맵 수
kernel_size : 컨볼루션 커널의 (행, 열) => 필터 사이즈
padding : 경계 처리 방법
-‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
-‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.

이 훈련결과를 어떻게 해석할 수 있을까요?
⇒ 과대적합
왜 과대적합이 되었을까요?
스트라이드가 크면 제대로 학습을 못해서 1이면 더 자세히 학습합니다.
한 가지 이유로 단정하기는 어렵지만 가장 성능이 안 좋게 나온 중점적인 이유를 찾는다면 이미지 전처리가 제대로 되어있지 않습니다. 노이즈 데이터가 많습니다.
tf.keras.layers.RandomFlip, tf.keras.layers.RandomRotation, tf.keras.layers.RandomZoom
이런 전처리 기능을 사용하면 이미지를 어떻게 변환할까요?
플립 로테이션 줌
⇒접고 돌리고 땡기고
지금까지 진행내용 정리
- 지금 실습은 TF공식예제의 이미지 분류 튜토리얼을 진행하고 있습니다.
- 해당 튜토리얼은 꽃 5가지 이미지를 학습하고 분류하는 예제입니다. ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips'] 5가지 꽃을 분류해 보는 예제입니다.
- 이미지 데이터를 불러와서 train, valid set 를 나누어 주었습니다.
- 리소스를 효율적으로 사용하기 위해 캐시 사용하는 예제를 봤고
- 0~1 사이로 정규화 해주는 예제를 봤습니다. => Rescaling 레이어에 추가해 줄 수도 있습니다.
- 기본 레이어로 학습을 했더니 성능이 안 좋게 나왔습니다. => 이미지에 노이즈가 너무 많았어요.
- 훈련 과정에서 과대적합을 막는 여러 가지 방법들이 있습니다. 이 튜토리얼에서는 데이터 증강을 사용하고 모델에 드롭아웃을 추가합니다.
- tf.keras.layers.RandomFlip, tf.keras.layers.RandomRotation, tf.keras.layers.RandomZoom 이런 전처리 기능을 사용하면 데이터 증강기법을 통해 이미지를 다양하게 생성해서 학습을 진행할 수 있습니다.
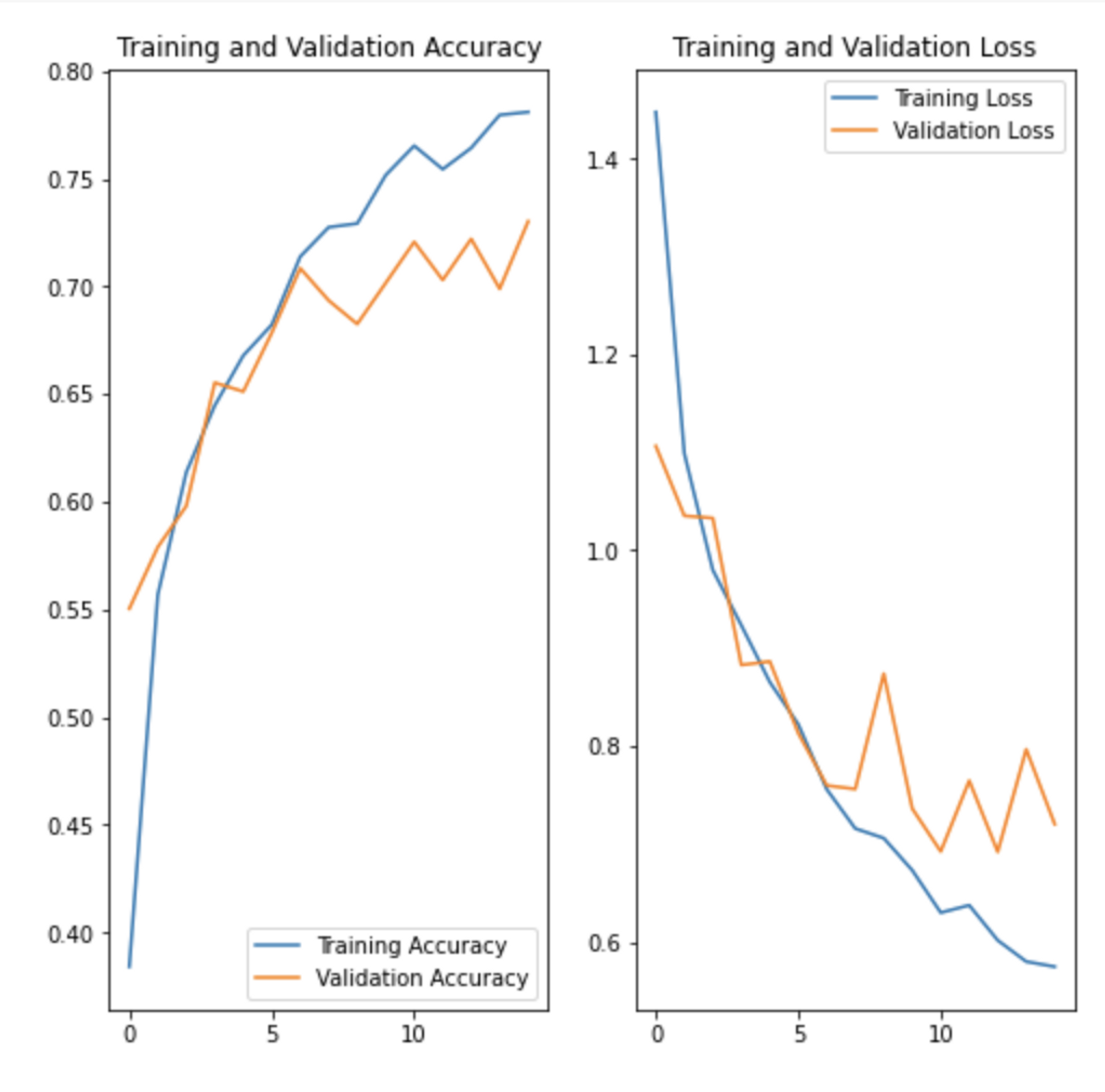
- 데이터 증강기법을 통해 오버피팅이 줄어든것을 확인해 볼 수 있습니다.
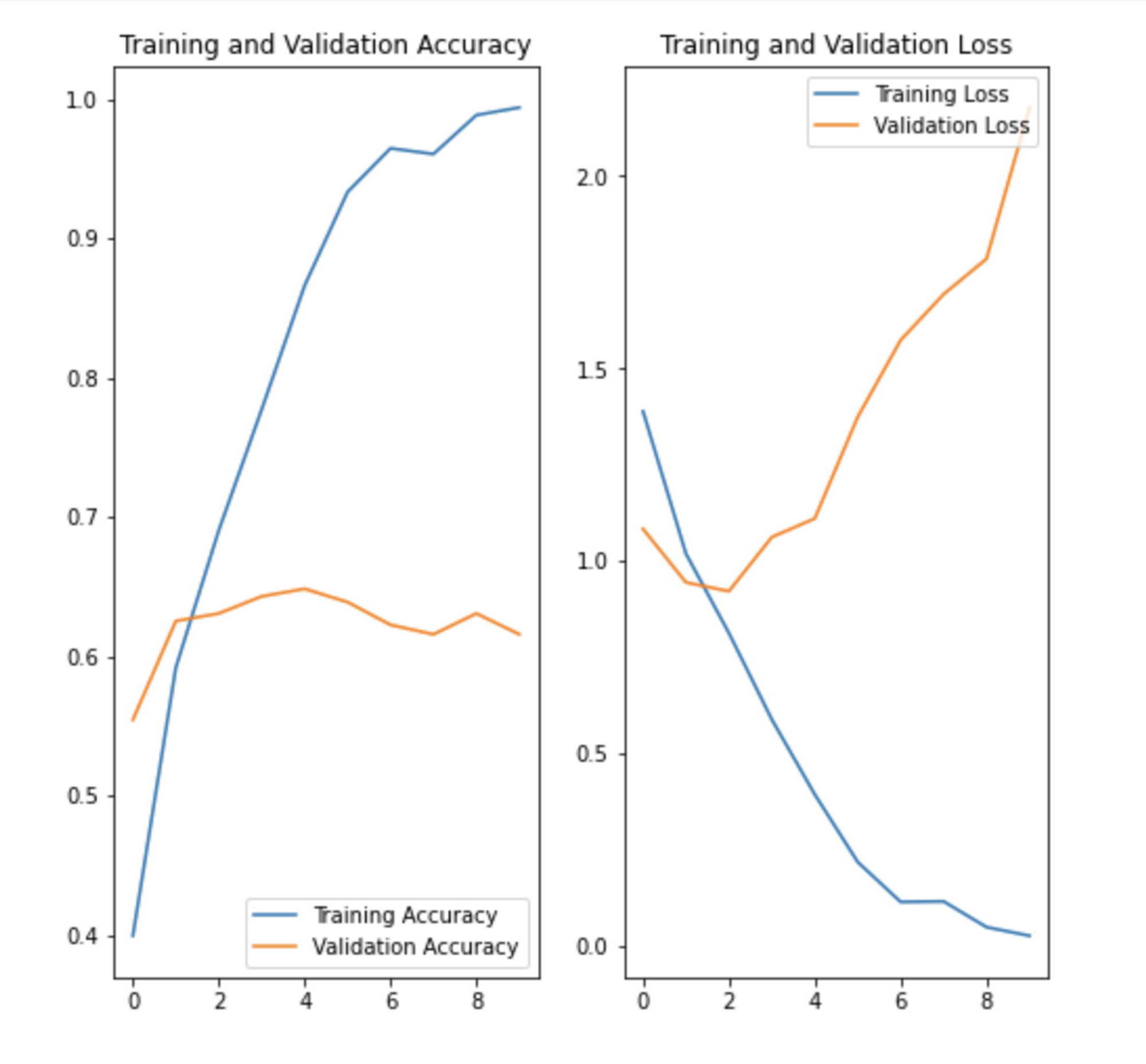
어떻게 해서 아래 그림처럼 오버피팅이 줄어들었을까요?
접돌땡을 통한 이미지 학습과 드랍아웃
(tf.keras.layers.RandomFlip, tf.keras.layers.RandomRotation, tf.keras.layers.RandomZoom)
전에햇던
MNIST(손글씨 이미지로 0~9 숫자), FMNIST(의류 10가지 이미지) 는 전처리가 잘 되어있기 때문에 기본 모델로 만들어도 99% 까지의 Accuracy가 나왔었습니다.
이번에 진행한 꽃 이미지에는 노이즈가 많기 때문에 Accuracy 가 데이터 증강, Dropout을 했을 때 0.6대에서 0.7정도로 정확도가 높아졌습니다.
[지금까지 한 실습은 TF공식예제에 있는 CNN 기본 레이어 구성과 데이터증강 기법을 알아보았습니다.]
1001 말라리아 혈액 이미지
이미지를 로드하는 방법에는 여러가지가 있습니다.
- matplotlib.pyplot imread()를 사용하는 방법
- PIL(Pillow) 로 불러오는 방법 => PIL 로 접고돌리고땡기고가 다 가능합니다. TF 내부에서도 PIL 이나 OpenCV를 사용해서 접고돌리고땡기고를 합니다. => 이미지 편집기를 만들 수도 있습니다.
- OpenCV로 불러오는 방법(Computer Vision)에 주로 사용하는 도구로 동영상처리 등에 주로 사용합니다.
Keras의 ImageDataGenerator는 다음과 같은 이미지 변환 유형을 지원합니다!
공간 레벨 변형
- Flip : 상하, 좌우 반전
- Rotation : 회전
- Shift : 이동
- Zoom : 확대, 축소
- Shear : 눕히기
픽셀 레벨 변형
- Bright : 밝기 조정
- Channel Shift : RGB 값 변경
- ZCA Whitening : Whitening 효과
이 이미지에서 피처맵은 몇 개 일까요?
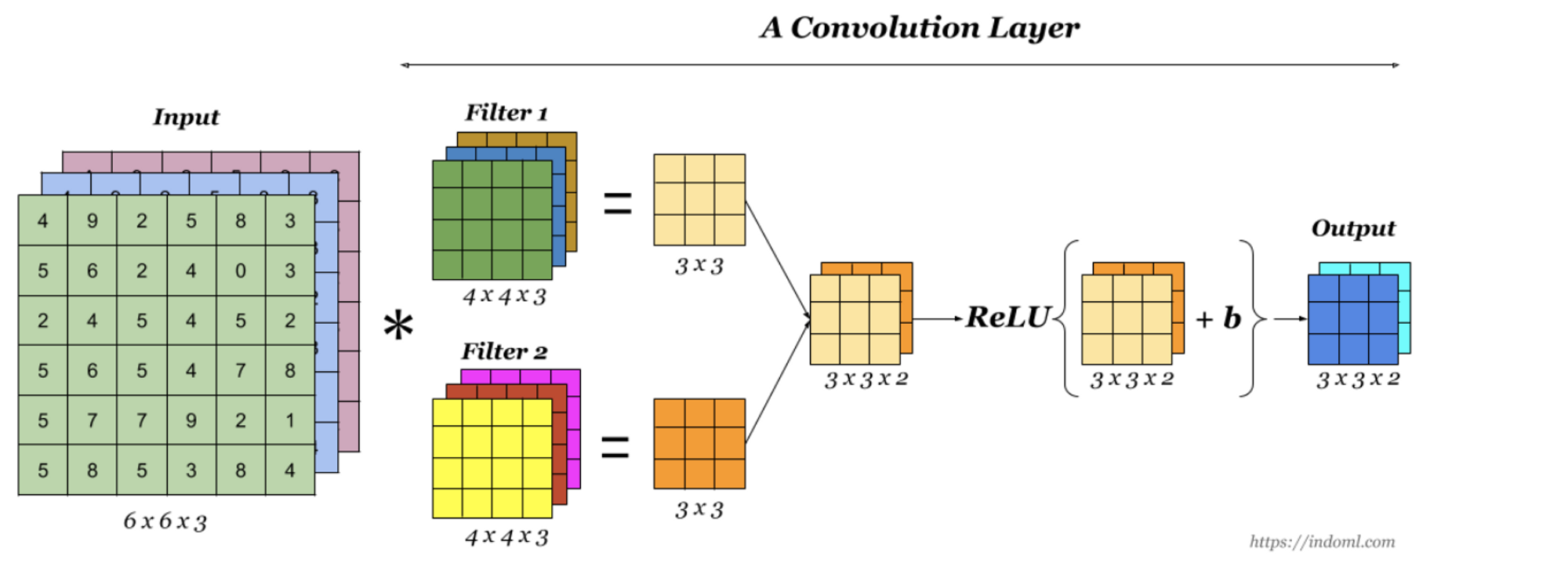
2개 - 필터가 2개를 통과해서(아래그림참조!)

필터1 에는 채널개수를 표기해줬는데, 필터 1에서 나온 피처맵에는 채널 개수가 없는 이유가 있을까요?
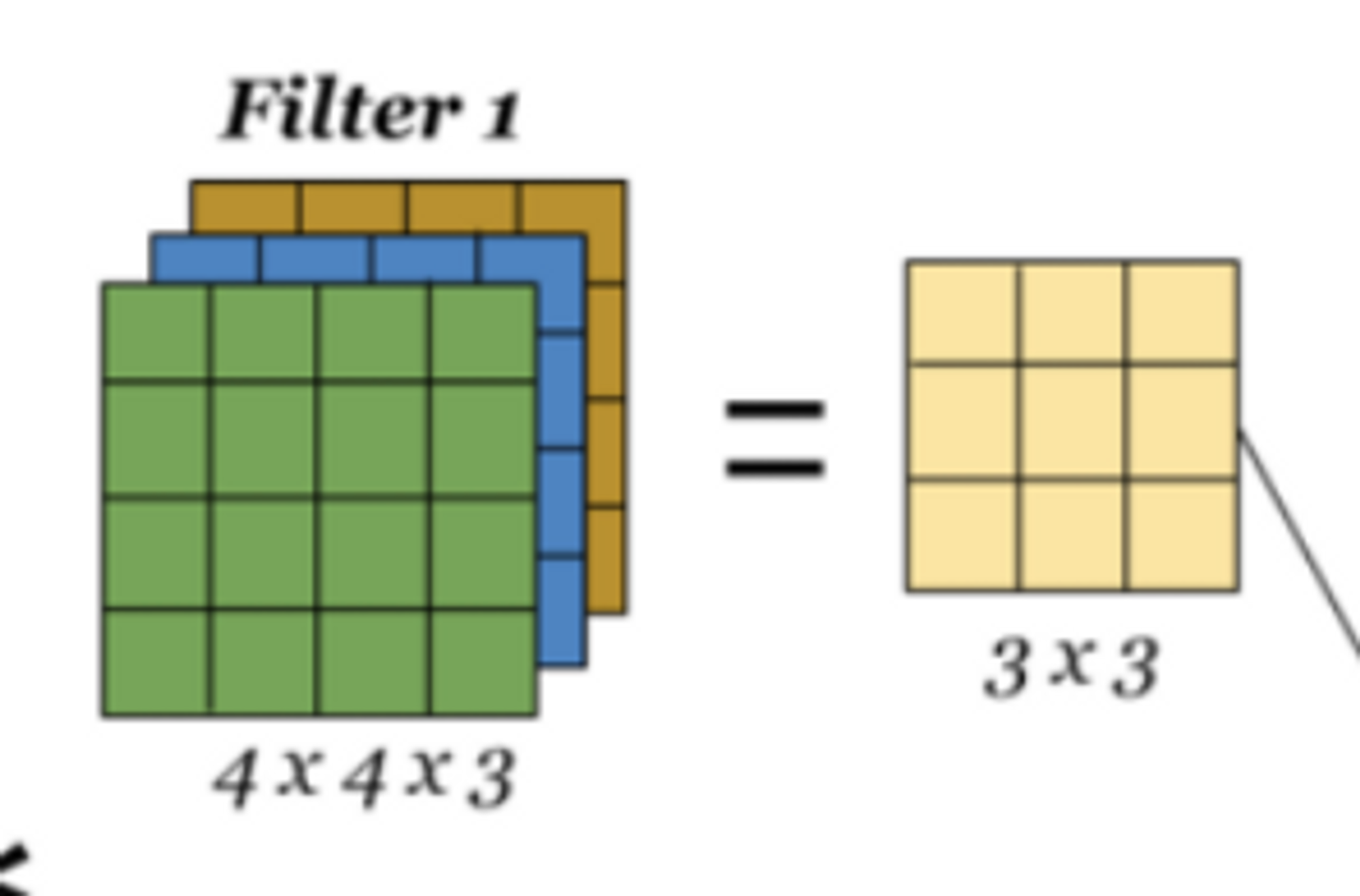

위 그림처럼 3개 각각 연산하고 1개로 출력해서
1002 번 파일 실습 => (주제) 말라리아 혈액도말 이미지 분류 실습,
=> (목적) TF공식 문서의 이미지 분류를 다른 이미지를 사용해서 응용해 보는 것입니다.
- 이미지 데이터 불러오기 wget 을 사용하면 온라인 URL 에 있는 파일을 불러올 수 있습니다.
논문(혈액도말 이미지로 말라리아 감염여부를 판단하는 논문)에 사용한 데이터셋을 불러왔습니다. - plt.imread 와 cv2(OpenCV) 의 imread 를 통해 array 형태로 데이터를 불러와서 시각화를 해서 감염된 이미지와 아닌 이미지를 비교해 봤습니다.
- TF.keras의 전처리 도구를 사용해서 train, valid set을 나눠주었습니다.
=> 레이블값을 폴더명으로 생성해 주게 됩니다.(현재 여기까지함) - 앞으로 할 내용은 CNN 레이어를 구성, 컴파일 하고 학습하고 정확도(Accuray) 성능을 비교해볼 예정입니다.
모델 층쌓기
- 비선형 활성화 함수가 없이 여러 개의 층을 쌓을 경우 기본 선형 활성화 함수를 사용하게 되므로 하나의 층을 가진 선형 모델과 성능이 비슷합니다.
- 은닉층에 비선형 활성화 함수를 추가하지 않으면 계산 자원과 시간을 낭비하는 결과를 초래하고 수치적으로 불안정성이 높아지게 됩니다.
- 이런 현상은 밀집 층 뿐만 아니라 아까 말한 합성곱 층과 같이 다른 종류의 층에도 적용되게 됩니다
- 층을 쌓을 때 "비선형 활성화 함수 없이" 두 개의 합성곱 층을 쌓는 경우 그냥 많은 커널을 가진 하나의 conv2d 층을 사용하는 것과 수학적으로 동일하기 때문에 비효율 적으로 합성곱 신경망을 만드는 것과 같으므로 주의해야한
| 입력데이터 종류와 이에 맞는 네트워크 구조 | |
| 벡터 데이터(시간이나 순서가 상관 없음) | MLP (밀집층) |
| 이미지 데이터(흑백 또는 컬러): | 2D 합성곱 신경망 |
| 스펙트로그램 오디오 데이터 | 2D 합성곱 신경망이나 순환 신경망 |
| 텍스트 데이터 | 1D 합성곱 신경망이나 순환 신경망 |
| 시계열 데이터(시간이나 순서가 중요함) | 1D 합성곱 신경망이나 순환 신경망 |
| 볼륨 데이터(예: 3D 의료 이미지) | 3D 합성곱 신경망 |
| 비디오 데이터(이미지의 시퀀스) | 3D 합성곱 신경망(모션 효과를 감지해야 하는 경우) 또는 특성 추출을 위해 프레임 별로 적용한 2D 합성곱 신경망과 만들어진 특성 시퀀스를 처리하기 위한 RNN이나 1D 합성곱 신경망의 조합 |
| 현재 저희는 이 중에 2D 합성곱 신경망을 통한 이미지 데이터 학습모델에 대해 진행하고 있습니다 | |
합성곱 신경망
합성곱 층은 입력받은 텐서에서 공간적으로 다른 위치에 기하학적 변환을 적용하여 국부적인 공간 패턴을 찾습니다.
이런 방식은 이동 불변성을 가진 표현을 만들기 때문에 합성곱 층을 매우 데이터 효율적으로 만들고 모듈화 시킵니다.
위와 같은 아이디어는 어떤 차원 공간에도 적용할 수 있기 때문에 1D(시퀀스), 2D(이미지나 이미지가 아니자만 사운드 스펙트로그램처럼 비슷한 표현), 3D(볼륨 데이터) 등입니다.
텐서플로우에서는 conv1d 층으로 시퀀스를 처리하고, conv2d층으로 이미지를 처리하고, conv3d 층으로 볼륨 데이터를 처리할 수 있습니다.
합성곱 신경망은 합성곱 층과 풀링 층을 쌓아서 구성하게 됩니다.
풀링 층은 공간적으로 데이터를 다운샘플링하고 이는 특성 개수가 늘어나게되면 후속 층이 합성곱 신경망의 입력 이미지에서 더 많은 공간을 바라보도록 특성 맵의 크기를 적절하게 유지시킵니다.
합성곱 신경망은 공간적인 특성 맵을 벡터로 바꾸기 위해 종종 flatten 층과 전역 풀링 층으로 끝납니다.
그리고 일련의 밀집층(MLP)로 처리하여 분류나 회귀 출력을 만들게 됩니다.
어떻게 해서 아래 그림처럼 오버피팅이 줄어들었을까요?
접돌땡을 통한 이미지 학습과 드랍아웃
기타 정리할것
커널사이즈는?
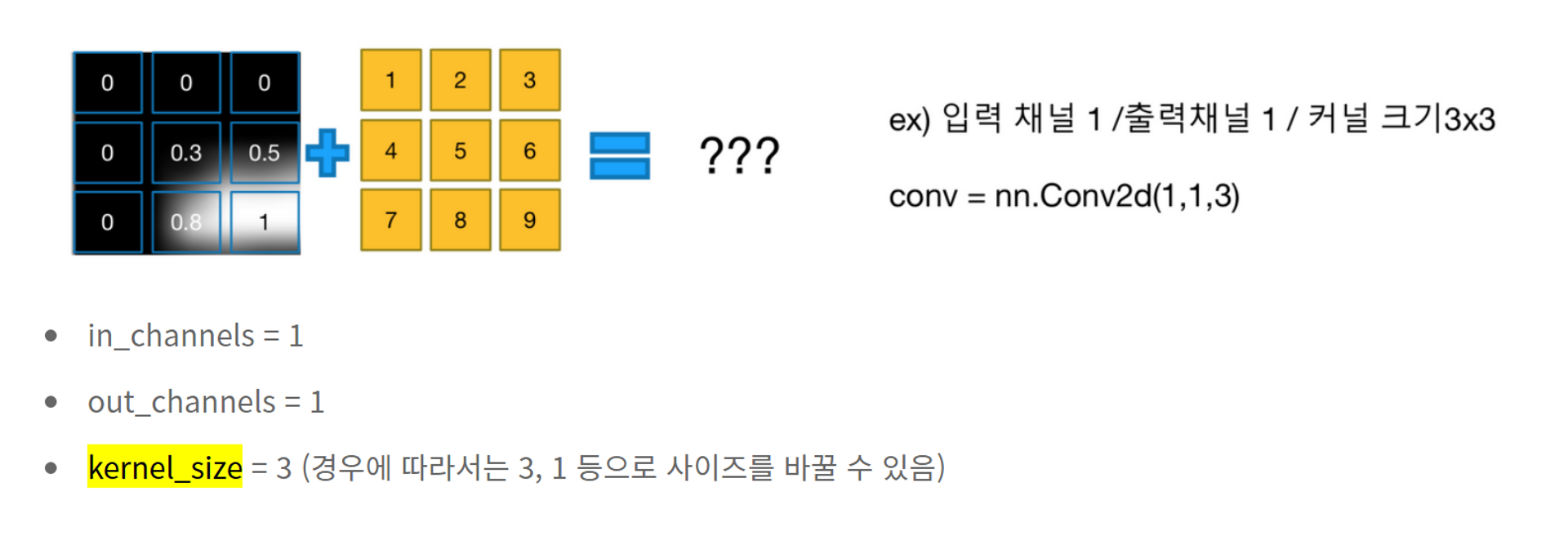
오답 노트 정리해보자
이미지의 채널 수 -> input_shape=(32, 32, 3))
3개!
피처맵의수 -> filters=32
32개
합성곱층(Convolution layer)
데이터의 특징을 추출 과정으로 필터를 사용하여 각 영역의 인접 데이터를 조사해 특징을 파악하여 한장으로 도출한 CNN의 핵심요소로서 이미지의 특정부분을 추상화하여 특정 층으로 표현 (예. 고양이의 눈, 귀, 입을 추상화)합니다.
패딩(Padding)
합성곱층에서 필터와 스트라이드 작용으로 특징맵(feature map)의 크기는 입력데이터보다 **작아지게** 되는 문제점을 보완하기 위해 나온 해결방안중 하나로
입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣으며 보통 0으로 값 채웁니다.
참고자료 :
멋쟁이 사자처럼 AI School 7기 박조은님 수업내용
'TIL > 딥러닝' 카테고리의 다른 글
| 12/13 화 NLP 자연어 전처리 (1) | 2022.12.14 |
|---|---|
| 12월 12일 NLP BOW TF-IDF (0) | 2022.12.13 |
| 12월 5일 딥러닝 CNN 기초 (0) | 2022.12.06 |
| 딥러닝과 머신러닝의 차이/ 활성화함수/ 기울기소실문제 (0) | 2022.12.03 |
| Tensorflow 101 딥러닝강의 정리해보기 (0) | 2022.11.27 |

댓글