오늘의 핵심 키워드 : NLP Tokenizer & Modeling ( RNN, LSTM, GRU )
1106실습 RNN (Recurrent Neural Network) 으로 텍스트 분류하기
RNN이란
순환 신경망(Recurrent neural network, RNN)은 인공 신경망의 한 종류로, 유닛간의 연결이 순환적 구조를 갖는 특징을 갖고 있다. 이러한 구조는 시변적 동적 특징을 모델링 할 수 있도록 신경망 내부에 상태를 저장할 수 있게 해주므로, 순방향 신경망과 달리 내부의 메모리를 이용해 시퀀스 형태의 입력을 처리할 수 있다. 따라서 순환 인공 신경망은 필기 인식이나 음성 인식과 같이 시변적 특징을 지니는 데이터를 처리하는데 적용할 수 있다.
순환 신경망이라는 이름은 입력받는 신호의 길이가 한정되지 않은 동적 데이터를 처리한다는 점에서 붙여진 이름으로, 유한 임펄스 구조와 무한 임펄스 구조를 모두 일컫는다. 유한 임펄스 순환 신경망은 유향 비순환 그래프이므로 적절하게 풀어서 재구성한다면 순방향 신경망으로도 표현할 수 있지만, 무한 임펄스 순환 신경망은 유향 그래프인고로 순방향 신경망으로 표현하는 것이 불가능하다.
순환 신경망은 추가적인 저장공간을 가질 수 있다. 이 저장공간이 그래프의 형태를 가짐으로써 시간 지연의 기능을 하거나 피드백 루프를 가질 수도 있다. 이와 같은 저장공간을 게이트된 상태(gated state) 또는 게이트된 메모리(gated memory)라고 하며, LSTM과 게이트 순환 유닛(GRU)이 이를 응용하는 대표적인 예시이다.
- time-step 을 갖는 데이터에 주로 사용, 예) 자연어(챗봇), 음성, 시계열데이터(주가 데이터), 심전도 데이터
- RNN, LSTM, GRU
- BPTT
- 시퀀스 데이터를 NN이나 CNN으로 처리하면 성능이 낮음
- 가중치가 데이터의 처리되는 순서와 상관없이 업데이트 되기 때문에 이전에 본 샘플을 기억할 수 없음
RNN 특징
- 기존 신경망과 다르게 결과값을 출력층 방향으로도 보내면서 다시 은닉층 노드의 다음 계산의 입려으로 보냄
- 다양한 길이의 입력 시퀀스를 처리할 수 있음
- 텍스트 분류나 기계 번역과 같은 다양한 자연어 처리로 사용됨
- 반복을 하는 노드가 있다고 생각하면 된다.
- 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징이 있음
텍스트 데이터 벡터화 하는 방법?
- 토큰화(str.split()) => one-hot-encoding => bag of words(min_df, max_df, analyzer, stopwords, n-gram)
- TF-IDF(너무 자주 등장하는 단어는 낮은 가중치, 특정 문서에만 자주 등장하는 단어는 높은 가중치)
- RNN 은 순서가 있는 데이터를 예측할 때 주로 사용하는데 BOW 순서를 보존하지 않습니다. 그래서 시퀀스 방식의 인코딩을 사용했습니다.
- Embedding =
> 여러 각도에서 단어와 단어 사이의 거리를 봅니다.
가까운 거리에 있는 단어는 유사한 단어이고
거리가 멀 수록 의미가 먼 단어 입니다
=> 의미를 좀 더 보존할 수 있게 되었습니다.
텍스트 데이터 전처리 방법?
- 정규표현식 => 텍스트 정규화
- 불용어
- 나, 너, 그것, 이것, 저것 처럼 자주 등장하지만 큰 의미를 갖지 않는 단어 제외
- 형태소 분석
- 의미가 없는 조사, 어미, 구두점 등을 제외
- 어간추출(stemming )
- 원형을 보존하지 않음
- 표제어표기법(lemmatization, )
- 원형을 보존
Modeling
내장 RNN
- keras.layers.SimpleRNN
- keras.layers.GRU
- keras.layers.LSTM
RNN용어
- 셀(cell) : RNN의 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드 (RNN의 반복 단위, 개별)
- 메모리셀(memory cell) : 이전의 값을 기억하는 일종의 메모리 역할을 수행하는 셀 (전체, RNNcell이라고도 함)
- 은닉상태(hidden state) : 은닉층의 메모리 셀에서 나온 값이 출력층 방향 또는 다음 시점의 자신 (다음 메모리 셀)에게 보내는 상태
- 이전 작업을 현재 작업과 연결할 수 있다는 큰 장점을 보유
- 인공신경망과 다르게 순환구조이므로 은닉층의 데이터를 저장하며 펼쳐진 형태로 순환구조로 확률값을 계산함
- RNN은 CNN처럼 깊게 층을 쌓지 않음
RNN연산종류
입력 갯수와 출력 갯수에 따른 유형으로, 입력과 출력의 길이에 따라서 달라지는 RNN의 다양한 형태
| One to one | 가장 기본적인 모델(simpleRNN) |
| One to many | 하나의 이미지를 문장으로 표현할 수 있음 ex) 앉아있는 고양이 등 |
| Many to one | 단어 시퀀스에 대해서 하나의 출력을 하는 구조로 감정 분류, 주가 등락을 통한 회사의 파산 여부 분류 등 |
| Many to many | 입력 시퀀스가 다른 시간 단계에서 비디오의 각 프레임의 기능 표현인 비디오 분류에도 사용 여러 개의 단어를 입력받아 여러 개의 단어로 구성된 문장을 명사, 동사, 형용사 등으로 구분 반환하는 번역기, 주가 예측, 인코더-디코더 |

RNN 역전파
- 모델에 맞는 역전파 방식을 찾으면 모델의 성능을 향상시킬 수 있음
- 시간에 따른 작업으로 역전파를 확장한 BPTT를 사용
한계점
- 한계점1 - 기울기 소실문제
- 복잡한 연산으로 인한 Gradient Vanishing / Exploding
- 시간을 통한 역전파의 프로세스는 일반 역전파보다 훨씬 더 많은 곱셈과 연산을 도입
- 해결책 : Truncated-Backpropagation Through (생략된 BPTT : 현재 time step에서 5 time step 이전까지 확인)
- 한계점 2 : 장기 의존성
- 비교적 짧은 시퀀스(sequence)에 대해서만 효과를 보이는 단점
- 장기 의존성 문제(the problem of Long-Term Dependencies)
- RNN의 시점(time step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생
⇒ 초기 입력이 잊혀져 예측 성능이 떨이짐 - 메모리 셀, 입력 게이트, 출력 게이트, 망각 게이트 이용 → 기울기 소실 문제 방지
- 해결책 : LSTM (장단기 메모리: Long Short Term Memory Network)
- SimpleRNN의 return_sequences : 다음 RNN층으로 넘길것인지 여부, 마지막층일 경우 False (=Default)
- 메모리 셀, 입력 게이트, 출력 게이트, 망각 게이트를 이용해 기존 순환 신경망(RNN)의 문제인 기울기 소실 문제를 방지
- 등장배경 : 입력의 길이가 길어져도 이전 정보를 더 오래 기억하는 학습 방법의 필요성|
- 이전 정보와 새로운 정보를 계산해서 activation 함수로 내보낸다
이전 값과 새로운 값을 입력을 받아 시그모이드 연산을 한다
ex) 시그모이드로 0.1이 들어갔다면 이전 정보의 10%만 사용하고 0.9가 들어갔다면 90%를 사용한다.
- 이전 정보와 새로운 정보를 계산해서 activation 함수로 내보낸다

과거 데이터를 얼마나 기억할지는 sigmoid로 결정
- 장점: 각각의 메모리 컨트롤이 가능하고 결과값이 컨트롤이 가능
- 단점: 메모리가 덮어씌워 질 가능성이 있고 연산속도가 느림
- LSTM의 구조
- Input -> Input Gate -> Memory Cell↑ -> Output Gate -> Output
- LSTM의 특징
- Cell State라고 불리는 특징층을 하나 더 넣어 Weight를 계속 기억할 것인지 결정
- 셀 상태(Cell state)는 정보를 추가하거나 삭제하는 기능을 담당 -> LSTM은 과거의 데이터를 계속해서 업데이트
- 기존 RNN의 경우, 정보와 정보사이의 거리가 멀면, 초기의 Weight값이 유지되지 않아 학습능력이 저하됨
- 장점 : 각각의 메모리 컨트롤이 가능하다. / 결과값이 컨트롤이 가능하다.
- 단점 : 메모리가 덮어씌워 질 가능성이 있다. / 연산속도가 느리다.
과거 데이터를 얼마나 기억할지는 sigmoid로 결정
- 장점: 각각의 메모리 컨트롤이 가능하고 결과값이 컨트롤이 가능
단점: 메모리가 덮어씌워 질 가능성이 있고 연산속도가 느림
과거 데이터를 얼마나 기억할지는 sigmoid로 결정
- 장점: 각각의 메모리 컨트롤이 가능하고 결과값이 컨트롤이 가능
- 단점: 메모리가 덮어씌워 질 가능성이 있고 연산속도가 느림
GRU
- LSTM을 변형시킨 알고리즘으로 기울기 소실 문제 해결
- LSTM은 초기의 가중치가 지속적으로 업데이트 되었지만
GRUs는 update Gate와 Reset Gate를 추가하여 과거의 정보를 어떻게 반영할 것인지 결정
(GRU는 게이트 2개, LSTM은 3개)
- 장점: 연산속도가 빠르고 LSTM처럼 덮어씌워질 가능성이 없음
- 단점: 메모리와 결과값 컨트롤이 불가
- update gate: 과거의 상태를 반영하는 gate
- reset gate: 현 시점 정보와 과거 시점 정보의 반영 여부를 결정
Bidirectional RNN
- 순차 RNN 학습 방향에는 한계 (정보의 불균형) → 양방향의 학습을 통해서 해결
- 2개의 은닉층으로 구성 (서로 연결 X)
- 전방향 상태(Forward States) 정보를 가진 은닉층
- 후방향 상태(Backward States) 정보를 가진 은닉층
- 입력값은 2개의 은닉층에 모두 전달되지만 서로 반대방향으로 진행
- 출력층도 이 두 은닉층의 값을 받아 최종 출력값 계산
RNN모델 구조


순차 RNN 학습 방향에는 한계가 있기 때문에 양방향의 학습을 통해서 해결하는 기법입니다
순차 RNN으로만 하면 날이, 너무만 보고 날씨의 상태를 파악해야하지만 양방향 학습을 이용하면 켰다,
에어컨을 보고 날씨의 상태를 더 잘 유추할 수 있습니다
1106 레이어 만들기
# # # Simple RNN 레이어를 사용한 모델을 정의합니다.
model = Sequential()
# 입력층-임베딩 층
model.add(Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=max_length))
# embedding 층 만들기
model.add(Bidirectional(SimpleRNN(units=64, return_sequences=True)))
# return sequences: 시퀀스 반환 여부 (는 기본값이 False / 다음 시퀀스가 있다면 True로 지정)
model.add(Bidirectional(SimpleRNN(units=64, return_sequences=True)))
# 출력층
model.add(SimpleRNN(units=64))
model.add(Dense(n_class, activation="softmax"))
# train_test_split 으로 학습과 예측에 사용할 데이터를 나눕니다.
# 시계열 데이터는 train_test_split 으로 나누지 않지만
# 여기에서는 각각의 문서가 순서가 있지는 않기 때문에 섞어서 나눠도 무방합니다.
# 8:2 로 나누겠습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y_onehot, stratify=y_onehot, test_size=0.2, random_state=42)
# stratify의 유무차이가 validation_split 사용의 성능을 구분 해줌
# rain_test_split으로 나누면 더 좋은 성능을 낸다(균형있게 validation data를 나눌 수 있음)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
주로 오류가 발생하는 곳
=> input_shape, compile 오타,RNN에서 레이어 설정을 잘 못 했을 때 등 발생하며
fit 을 할 때 오류메시지를 확인하면 어떤 오류메시지인지 확인할 수 있습니다.
단어임베딩
단어 임베딩 | Text | TensorFlow
KerasCV, 온디바이스 ML 등을 사용한 확산 모델을 다루는 WiML 심포지엄의 세션을 확인하세요. 주문형 시청 이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English 단어 임베딩 컬렉션을
www.tensorflow.org
단어 임베딩은 유사한 단어가 유사한 인코딩을 갖는 효율적이고 조밀한 표현을 사용하는 방법을 제공합니다. 중요한 것은 이 인코딩을 직접 지정할 필요가 없다는 것입니다.
임베딩은 부동 소수점 값의 조밀한 벡터입니다(벡터의 길이는 사용자가 지정하는 매개변수임). 임베딩에 대한 값을 수동으로 지정하는 대신 학습 가능한 매개변수입니다(모델이 조밀한 계층에 대한 가중치를 학습하는 것과 같은 방식으로 학습 중 모델에 의해 학습된 가중치).
큰 데이터 세트로 작업할 때 8차원(작은 데이터 세트의 경우), 최대 1024차원의 단어 임베딩을 보는 것이 일반적입니다. 더 높은 차원의 임베딩은 단어 간의 세분화된 관계를 캡처할 수 있지만 학습하는 데 더 많은 데이터가 필요합니다.

위는 단어 임베딩에 대한 다이어그램입니다. 각 단어는 부동 소수점 값의 4차원 벡터로 표시됩니다. 임베딩을 생각하는 또 다른 방법은 "룩업 테이블"입니다.
이러한 가중치를 학습한 후 테이블에서 해당하는 조밀한 벡터를 조회하여 각 단어를 인코딩할 수 있습니다.
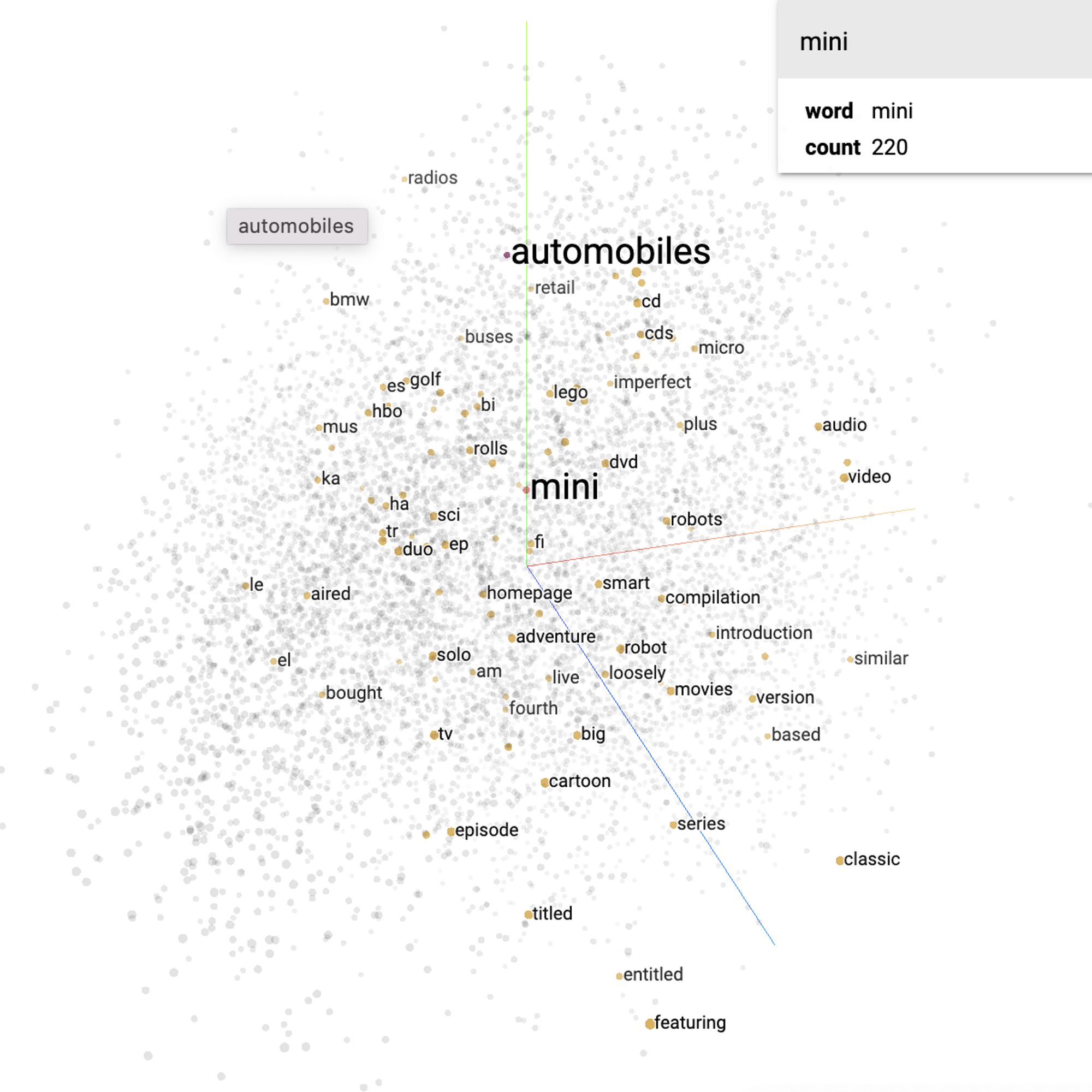
해당 TextVectorization은 단어의 맥락을 고려하는 것이 아니라 오직 빈도수에 따른 단어 사전의 위치만 알려주기 때문에 해당 TextVectorization으로 학습하는 것은 크게 의미가 없습니다.
따라서 TextVectorization를 Embedding을 시켜주고 좌표로 표시할 수 있습니다. 맥락이 비슷하면 좌표에서 거리를 가깝게 옮겨주고 맥락이 반대면 좌표에서 거리를 멀게 설정해줍니다. 이 거리를 설정하는 과정은 LSTM에서 학습 후 조정해주게 됩니다.
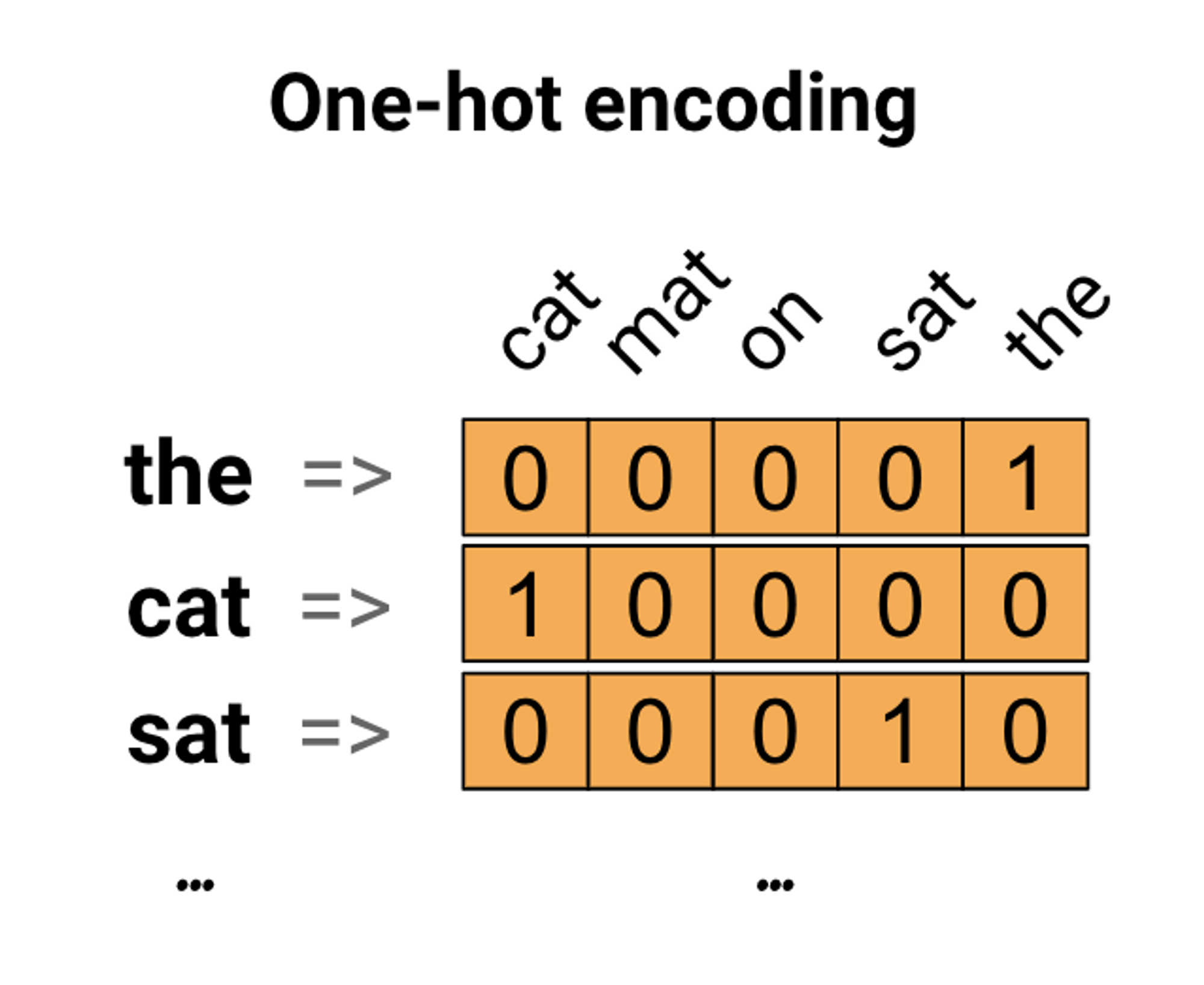
원-핫 인코딩
첫 번째 아이디어로 어휘의 각 단어를 "원 핫"으로 인코딩할 수 있습니다.
"고양이가 매트 위에 앉았다"라는 문장을 생각해 보십시오.
이 문장의 어휘(또는 고유한 단어)는 (cat, mat, on, sat,)입니다.
각 단어를 나타내기 위해 길이가 어휘와 동일한 0 벡터를 만든 다음 단어에 해당하는 인덱스에 1을 배치합니다. 이 접근 방식은 다음 다이어그램에 나와 있습니다.
출력값이 어떤 형태로 나올까요?

0~1 사이의 확률값
1107 시계열 예측
시계열 예측 | TensorFlow Core
KerasCV, 온디바이스 ML 등을 사용한 확산 모델을 다루는 WiML 심포지엄의 세션을 확인하세요. 주문형 시청 시계열 예측 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류
www.tensorflow.org
이렇게 정규화를 하면 어떻게 변환이 될까요?

standard
평균을 0, 표준편차를 1로 만들어준다.
그러나 이상치가 있다면 평균과 표준편차에 영향을 미쳐 변환된 데이터의 확산은 매우 달라지게 되므로 이상치가 있는 경우 균형 잡힌 척도를 보장할 수 없다.
정규화부분 문서
시계열 예측 | TensorFlow Core
KerasCV, 온디바이스 ML 등을 사용한 확산 모델을 다루는 WiML 심포지엄의 세션을 확인하세요. 주문형 시청 시계열 예측 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류
www.tensorflow.org
GPU가 있는지 없는지 확인하는 코드
gpu_info = !nvidia-smi
gpu_info = '\\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info)참고자료 :
멋쟁이 사자처럼 AI School 7기 수업내용
'TIL > 딥러닝' 카테고리의 다른 글
| 12/19 월 시계열 예측 ,비즈니스 데이터 분석 (0) | 2022.12.20 |
|---|---|
| (Stop Words,TF-IDF ,Bag of Words 방식과 시퀀스 방식, RNN과 LSTM) (1) | 2022.12.18 |
| 12/13 화 NLP 자연어 전처리 (1) | 2022.12.14 |
| 12월 12일 NLP BOW TF-IDF (0) | 2022.12.13 |
| 12월 6일 딥러닝 말라리아 CNN 분류 , cnn개념 용어 정리 !!! (1) | 2022.12.08 |

댓글